上一篇(vLLM(1): 背景、原理和核心技术)介绍了 vLLM 的背景、原理和核心技术,本文主要介绍 vLLM 的架构和工作流程。vLLM 是一项耦合了工程调度、分布式和推理的 LLM Domian Specific 框架,所以整体架构与以往的 ML serving system 有很大区别。本文将结合代码、从调用接口和工作流程的角度去拆解 vLLM 的架构和组件。
架构 #
用户接口 #
vLLM 向用户提供了两种调用方法(Fig. 1):
- Offline Batched Inference(同步,离线推理)
- API Server For Online Serving(异步,在线推理):
- OpenAI-Compatible API Server:兼容 OpenAI 请求格式(OpenAI Completions API, OpenAI Chat API)
- Simple Demo API Server
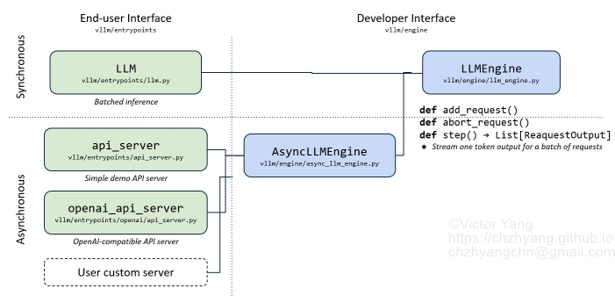
vLLM 实现了一个核心模块 LLMEngine,并封装了上述两种调用,而 LLMEngine 运行时是动态的batch_size。基于 Fig. 1,同步的离线批处理,实际也是按动态 batch size 来实现的。异步的在线推理所基于的 AsyncLLMEngine 是对 LLMEngine 的继承。所以,本文以 Offline Batched Inference 为入口来分析 LLMEngine 的运作。
核心架构 #
从 Fig. 1 可以看出 LLMEngine 是整个 vLLM 的核心,所以这部分主要分析 LLMEngine 的架构。
从架构的角度,如 Fig. 2 所示,LLMEngine 由两大块组成:
- Scheduler(Centralized Controller): 它和 LLMEngine 所在的进程是 CPU 上的同一进程,主要负责在每一个推理阶段选择 SequenceGroup 推送给 Distributed Workers 做推理。
- Distributed Workers:分布式管理系统,负责加载模型,执行推理。
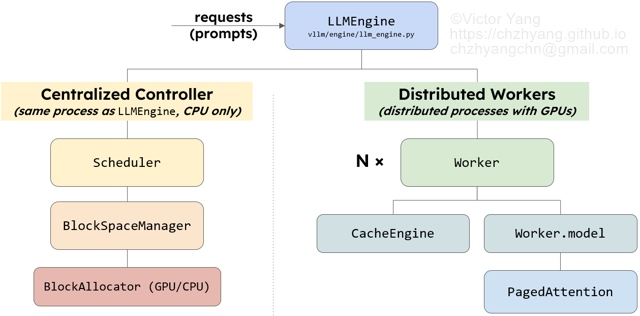
从代码角度,LLMEngine Class 有2个重要对象和2个重要方法。
2个重要对象:
- scheduler
- model_executor,是对 Distributed Workers(
/vllm/worker) 的封装,包括cpu_executor、gpu_executor(单卡推理)、ray_gpu_executor(基于Ray的分布式推理)、openvino_executor(基于Intel的Openvino推理)、ray_tpu_executor等。
2个重要方法:
- add_request():负责将 req 封装成推理时调度的基本单元 SequenceGroup
- step(): 负责执行一次推理(prifill 和 decode 都算一次推理,vllm 中 prifill 和 decode 并没有 fuse,所以同一 batch 中的 seq 只能同时做 prefill或做 decode)
那么 Scheduler 和 Distributed Workers(model_executor) 的具体是怎么工作的呢?下面将结合工作流程进行详细分析。
工作流程 #
如前文所述,以 Offline Batched Inference 为入口来分析 LLMEngine 的工作流程,代码如下:
from vllm import LLM, SamplingParams
prompts = ["Hello,",
"The president of the UK is",
"The capital of USA is",
"The future of AI is",]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
# Initilization
llm = LLM(model="meta/llama2-13b")
# Inference
outputs = llm.generate(prompts, sampling_params)
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
初始化阶段 #
LLMEngine 的初始化阶段(推理正式开始前),入口为这段代码 llm = LLM(model=“meta/llama2-13b") ,主要做了两件事(Fig. 3):
- 加载模型
- 预分配显存
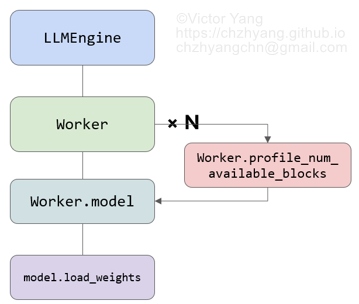
其中,预分配显存是指通过模拟推理来评估 gpu/cpu 上可以分配多少显存给 KVCache,以及 KVCache 物理块的数量。这个步骤在代码里被称为 profile_num_available_blocks,GPU 上的工作流程如下:
-
模拟推理请求 LLMEngine 有两个参数:
max_num_seqs(default=256): LLMEngine 最多能处理的 seq 数量max_num_batched_tokens(default=2048):LLMEngine 最多能处理的 token 数量
根据这两个参数,LLMEngine 可以预估平均一个 seq 有 max_num_batched_tokens // max_num_seqs 个token。如果按照两个参数的默认值,就可以模拟 8 个 token 数量为 256 的 seq。
-
评估能分配给 KVCache 的显存 通过对模拟的假数据执行一次推理来计算能分配给 KVCache 的显存 \(M_{kv}\),公式如下: $$ M_{kv} = M_{gpu} - M_{infer} $$ 其中,\(M_{gpu}\) 表示 GPU 内存大小;\(M_{infer}\) 表示不使用 KVCache 进行推理时占用的内存
-
计算可分配的 KVCache Block 总数 \(N_{block}\) $$ N_{block} = \frac{M_{kv}}{B} $$ 其中,\(M_{kv}\) 表示分配给KVCache的显存,\({B}\) 表示一个 block 占的显存,单位是 bytes。
代码中的
block_size(默认为16)表示一个 block 中可以放多少个 token 的 k 或 v。一个 block 占的显存 \({B}\) 的计算公式如下:B = 2* block_size * num_heads * head_size * num_layers * dtype_size其中, 2 表示 K 和 V;dtype_size 表示数据精度对应的大小(bytes),例如 fp32 就是 4。
-
预分配 KVCache 显存
在 GPU上,以 torch.zeros tensor 的方式分配 \(M_{kv}\) bytes 的 KVCache 显存。该工作在代码中由 Worker 上的 CacheEngine 在初始化时执行,相关代码如下:
class CacheEngine: def __init__( self, cache_config: CacheConfig, model_config: ModelConfig, parallel_config: ParallelConfig, device_config: DeviceConfig, ) -> None: # Initialize the cache. self.gpu_cache = self._allocate_kv_cache( self.num_gpu_blocks, self.device_config.device_type) self.cpu_cache = self._allocate_kv_cache(self.num_cpu_blocks, "cpu")def _allocate_kv_cache( self, num_blocks: int, device: str, ) -> List[torch.Tensor]: """Allocates KV cache on the specified device.""" kv_cache_shape = self.attn_backend.get_kv_cache_shape( num_blocks, self.block_size, self.num_kv_heads, self.head_size) pin_memory = is_pin_memory_available() if device == "cpu" else False kv_cache: List[torch.Tensor] = [] for _ in range(self.num_attention_layers): # null block in CpuGpuBlockAllocator requires at least that # block to be zeroed-out. # We zero-out everything for simplicity. kv_cache.append( torch.zeros(kv_cache_shape, dtype=self.dtype, pin_memory=pin_memory, device=device)) return kv_cache
推理阶段 #
初始化完成后,vLLM 接受到的 Request 会被 Web Server 发送给 LLMEngine(Fig. 2),入口代码是:
outputs = llm.generate(prompts, sampling_params)
即 /vllm/entrypoints/llm.py 的 llm.generate(),这个方法主要通过 LLMEngine 做两件事:
-
调用
llm_engine.add_request()将 req 解析为 tokens,并封装成 SequenceGroup(SG) 对象,具体调用栈:self._validate_and_add_requests()->self._add_request()->self.llm_engine.add_request() -
迭代得调用
llm_engine.step(),调用栈:self._run_engine()->self.llm_engine.step()在每个 step() 中:
- 调用 Scheduler 决定哪些 SG 可以进行推理,也会通过 block table 做好 logical block 与 physical block 的映射。调用栈:
llm_engine.step()->self.scheduler[0].schedule() - 将 SchedulerOutput 封装为 ExecuteModelRequest 发送给 Distributed Workers(distributed executor)执行推理。调用栈:
llm_engine.step()->self.model_executor.execute_model()
在 1 次推理中,所有的 SG 要么一起做 prefill,要么一起做 decode。
- 调用 Scheduler 决定哪些 SG 可以进行推理,也会通过 block table 做好 logical block 与 physical block 的映射。调用栈:
总结 #
本文介绍了 vLLM 的架构,结合 LLMEngine 分析了工作流程。本系列的后续文章将深入分析LLMEngine 的两个重要组件: Scheduler 和 Distributed Workers。
Reference #
- vLLM blog
- vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention
- Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. 2022. Flashattention: Fast and memory-efficient exact attention with io-awareness. Advances in Neural Information Processing Systems 35 (2022), 16344–16359