本文主要介绍如何一步步使用 python 和 pytorch 加载 llama3 并进行文本生成,并分析llama3的结构和各层的参数,也可以参考本文的jupyter notebook: implement-llama3
Pre-requirements #
Download Llama3 weights from https://llama.meta.com/llama-downloads/
pip install -r requirements.txt
Use tiktoken as the tokenizer
from pathlib import Path
import tiktoken
from tiktoken.load import load_tiktoken_bpe
import torch
import json
import matplotlib.pyplot as plt
tokenizer_path = "/home/sdp/models/Meta-Llama-3-8B/tokenizer.model"
special_tokens = [
"<|begin_of_text|>",
"<|end_of_text|>",
"<|reserved_special_token_0|>",
"<|reserved_special_token_1|>",
"<|reserved_special_token_2|>",
"<|reserved_special_token_3|>",
"<|start_header_id|>",
"<|end_header_id|>",
"<|reserved_special_token_4|>",
"<|eot_id|>", # end of turn
] + [f"<|reserved_special_token_{i}|>" for i in range(5, 256 - 5)]
mergeable_ranks = load_tiktoken_bpe(tokenizer_path)
tokenizer = tiktoken.Encoding(
name=Path(tokenizer_path).name,
pat_str=r"(?i:'s|'t|'re|'ve|'m|'ll|'d)|[^\r\n\p{L}\p{N}]?\p{L}+|\p{N}{1,3}| ?[^\s\p{L}\p{N}]+[\r\n]*|\s*[\r\n]+|\s+(?!\S)|\s+",
mergeable_ranks=mergeable_ranks,
special_tokens={token: len(mergeable_ranks) + i for i, token in enumerate(special_tokens)},
)
tokenizer.decode(tokenizer.encode("Im AI!"))
Load model weights and model config #
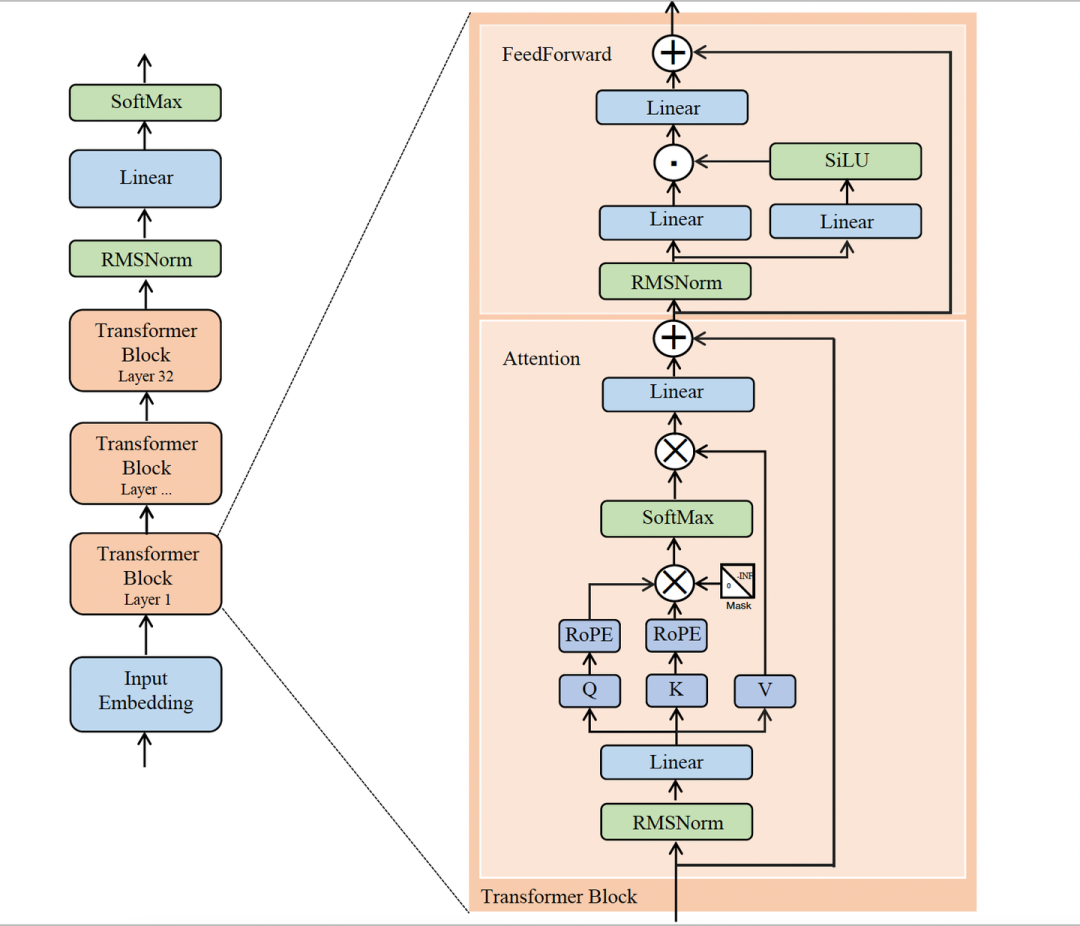
模型权重:
model_path="/home/sdp/models/Meta-Llama-3-8B/consolidated.00.pth"
model = torch.load(model_path)
print(json.dumps(list(model.keys())[:20], indent=4))
"tok_embeddings.weight",
"layers.0.attention.wq.weight",
"layers.0.attention.wk.weight",
"layers.0.attention.wv.weight",
"layers.0.attention.wo.weight",
"layers.0.feed_forward.w1.weight",
"layers.0.feed_forward.w3.weight",
"layers.0.feed_forward.w2.weight",
"layers.0.attention_norm.weight",
"layers.0.ffn_norm.weight",
"layers.1.attention.wq.weight",
"layers.1.attention.wk.weight",
"layers.1.attention.wv.weight",
"layers.1.attention.wo.weight",
"layers.1.feed_forward.w1.weight",
"layers.1.feed_forward.w3.weight",
"layers.1.feed_forward.w2.weight",
"layers.1.attention_norm.weight",
"layers.1.ffn_norm.weight",
"layers.2.attention.wq.weight"
模型的配置信息:
- 32 个 DecoderLayer
- 每个 AttentionLayer(GQA) 有 32 个 Query Head, 8 个 KV Group
- 每 4 个 Head 共享一个 KV,
- 每个 Q head 的 size 是 dim/32=128
- 每个 KV group 的 size 是 dim/4=1024
- 分词表大小为128256
with open("/home/sdp/models/Meta-Llama-3-8B/params.json", "r") as f:
config = json.load(f)
config
{'dim': 4096,
'n_layers': 32,
'n_heads': 32,
'n_kv_heads': 8,
'vocab_size': 128256,
'multiple_of': 1024,
'ffn_dim_multiplier': 1.3,
'norm_eps': 1e-05,
'rope_theta': 500000.0}
将config信息存入变量
dim = config["dim"]
n_layers = config["n_layers"]
n_heads = config["n_heads"]
n_kv_heads = config["n_kv_heads"]
vocab_size = config["vocab_size"]
multiple_of = config["multiple_of"]
ffn_dim_multiplier = config["ffn_dim_multiplier"]
norm_eps = config["norm_eps"]
rope_theta = torch.tensor(config["rope_theta"])
Prepare prompt tokens #
prompt = "the answer to the ultimate question of life, the universe, and everything is "
tokens = [128000] + tokenizer.encode(prompt)
print(len(tokens)) # len=17
print(tokens)
tokens = torch.tensor(tokens)
prompt_split_as_tokens = [tokenizer.decode([token.item()]) for token in tokens]
print(prompt_split_as_tokens)
input 的 tokens 长度是17,即 seq_len = 17, 则此时可以推算出的 model 中部分参数维度:
seq_len 17
embed_dim 4096
embed_output (seq_len, embed_dim) (17, 4096)
attention q_head_num 32
attention q_head_size 128
attention kv_group_num 4
attention kv_head_size 1024
attention.wq.weight (q_head_num, seq_len, q_head_size) (32, 17, 128)
attention.wk.weight (kv_group_num, seq_len, kv_head_size) (4, 17, 1024)
attention.wv.weight (kv_group_num, seq_len, kv_head_size) (4, 17, 1024)
attention.wo.weight
feed_forward.w1.weight
feed_forward.w3.weight
feed_forward.w2.weight
attention_norm.weight
ffn_norm.weight
Embedding layer #
将input tokens转换为embedding,(17,1) -> (17,4096)
embedding_layer = torch.nn.Embedding(vocab_size, dim)
embedding_layer.weight.data.copy_(model["tok_embeddings.weight"])
token_embeddings_unnormalized = embedding_layer(tokens).to(torch.bfloat16)
token_embeddings_unnormalized.shape # torch.Size([17, 4096])
RMS Normalization #
用RMS对embedding进行归一化,这里使用torch的rsqrt求均值方差, 归一化后的Tensor形状不变
[Todo: CUDA LayerNorm Kernel] 更好的方法是编写专用的 RMSNorm 算子(kernel)
def rms_norm(tensor, norm_weights):
return (tensor * torch.rsqrt(tensor.pow(2).mean(-1, keepdim=True) + norm_eps)) * norm_weights
token_embeddings = rms_norm(token_embeddings_unnormalized, model["layers.0.attention_norm.weight"])
token_embeddings.shape # torch.Size([17, 4096])
接下来实现 Model 的主体 DecoderLayer
DecoderLayer #
一共 32 个 DecoderLayer, 每个 Layer 含有 1 个 AttentionLayer 和 1 个 FFNLayer
为了方便识别,假设 embedding 层的输出 token_embeddings_unnormalized 为 x
每一层DecoderLayer的工作流程:
- x -> rmsnorm -> AttentionLayer -> attention output
- attention output += x
- attention output -> rmsnorm -> FFNLayer -> ffn output
- output = ffn output + attention output
AttentionLayer #
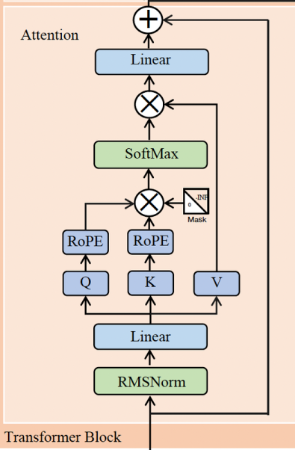
输入为norm后的 x, 维度为(17, 4096), 查看 attention weight 的维度
print(
model["layers.0.attention.wq.weight"].shape,
model["layers.0.attention.wk.weight"].shape,
model["layers.0.attention.wv.weight"].shape,
model["layers.0.attention.wo.weight"].shape
)
# torch.Size([4096, 4096])
# torch.Size([1024, 4096])
# torch.Size([1024, 4096])
# torch.Size([4096, 4096])
attention 要计算 \(softmax(QK^T)V\), 其中 Q,K,V 都用 attention input(17, 4096) 与 相应的 weight(wq, wk, wv) 计算出来的, 则根据矩阵乘的原则可以推算出 QKV 各自的维度:
- Q (17, 128)
- K (17, 1024)
- V (17, 1024)
Query #
q_layer0 = model["layers.0.attention.wq.weight"]
head_dim = q_layer0.shape[0] // n_heads
q_layer0 = q_layer0.view(n_heads, head_dim, dim)
print(q_layer0.shape)
q_layer0_head0 = q_layer0[0]
print(q_layer0_head0.shape)
q_per_token = torch.matmul(token_embeddings, q_layer0_head0.T)
print(q_per_token.shape)
# torch.Size([32, 128, 4096])
# torch.Size([128, 4096])
# torch.Size([17, 128])
Q和V都要经过 RoPE 进行旋转位置编码, 因为注意力机制中对每个token没有序列位置的概念,第一个词和最后一个词在Q、K、V矩阵看来都是一样的,因此需要在Query中嵌入维度为[1x128]的位置编码。位置编码有多种方法,Llama模型采用的是旋转位置编码 RoPE
# 让 q 两两成对,共64对
q_per_token_split_into_pairs = q_per_token.float().view(q_per_token.shape[0], -1, 2)
print(q_per_token_split_into_pairs.shape)
# 句子中在index位置的一对查询向量,旋转角度为index*(rope_theta)
zero_to_one_split_into_64_parts = torch.tensor(range(64))/64
print(zero_to_one_split_into_64_parts)
freqs = 1.0 / (rope_theta ** zero_to_one_split_into_64_parts)
print(freqs)
# 构建freq_cis矩阵,存储句子中每个位置的、对查询向量每个值的旋转角度
freqs_for_each_token = torch.outer(torch.arange(17), freqs)
freqs_cis = torch.polar(torch.ones_like(freqs_for_each_token), freqs_for_each_token)
# 将每对查询向量转换为复数,之后进行与旋转角度进行点积操作
q_per_token_as_complex_numbers = torch.view_as_complex(q_per_token_split_into_pairs)
print(q_per_token_as_complex_numbers.shape)
q_per_token_as_complex_numbers_rotated = q_per_token_as_complex_numbers * freqs_cis
print(q_per_token_as_complex_numbers_rotated.shape)
# 把旋转后的查询向量转换回实数形式, 恢复原始维度
q_per_token_split_into_pairs_rotated = torch.view_as_real(q_per_token_as_complex_numbers_rotated)
print(q_per_token_split_into_pairs_rotated.shape)
q_per_token_rotated = q_per_token_split_into_pairs_rotated.view(q_per_token.shape)
print(q_per_token_rotated.shape)
torch.Size([17, 64, 2])
tensor([0.0000, 0.0156, 0.0312, 0.0469, 0.0625, 0.0781, 0.0938, 0.1094, 0.1250,
0.1406, 0.1562, 0.1719, 0.1875, 0.2031, 0.2188, 0.2344, 0.2500, 0.2656,
0.2812, 0.2969, 0.3125, 0.3281, 0.3438, 0.3594, 0.3750, 0.3906, 0.4062,
0.4219, 0.4375, 0.4531, 0.4688, 0.4844, 0.5000, 0.5156, 0.5312, 0.5469,
0.5625, 0.5781, 0.5938, 0.6094, 0.6250, 0.6406, 0.6562, 0.6719, 0.6875,
0.7031, 0.7188, 0.7344, 0.7500, 0.7656, 0.7812, 0.7969, 0.8125, 0.8281,
0.8438, 0.8594, 0.8750, 0.8906, 0.9062, 0.9219, 0.9375, 0.9531, 0.9688,
0.9844])
tensor([1.0000e+00, 8.1462e-01, 6.6360e-01, 5.4058e-01, 4.4037e-01, 3.5873e-01,
2.9223e-01, 2.3805e-01, 1.9392e-01, 1.5797e-01, 1.2869e-01, 1.0483e-01,
8.5397e-02, 6.9566e-02, 5.6670e-02, 4.6164e-02, 3.7606e-02, 3.0635e-02,
2.4955e-02, 2.0329e-02, 1.6560e-02, 1.3490e-02, 1.0990e-02, 8.9523e-03,
7.2927e-03, 5.9407e-03, 4.8394e-03, 3.9423e-03, 3.2114e-03, 2.6161e-03,
2.1311e-03, 1.7360e-03, 1.4142e-03, 1.1520e-03, 9.3847e-04, 7.6450e-04,
6.2277e-04, 5.0732e-04, 4.1327e-04, 3.3666e-04, 2.7425e-04, 2.2341e-04,
1.8199e-04, 1.4825e-04, 1.2077e-04, 9.8381e-05, 8.0143e-05, 6.5286e-05,
5.3183e-05, 4.3324e-05, 3.5292e-05, 2.8750e-05, 2.3420e-05, 1.9078e-05,
1.5542e-05, 1.2660e-05, 1.0313e-05, 8.4015e-06, 6.8440e-06, 5.5752e-06,
4.5417e-06, 3.6997e-06, 3.0139e-06, 2.4551e-06])
torch.Size([17, 64])
torch.Size([17, 64])
torch.Size([17, 64, 2])
torch.Size([17, 128])
Key #
经过 RoPE 后 的 Q 维度不变,下一步计算 K,计算方法与 Q 类似,也需要 RoPE, 但维度不同,因为 Q 有 32 个 head, 而 K 和 V 有 8 个 group head, 每个 K和V 被 4 个 Q 共享。
用于计算 K 的 权重维度是(1024, 4096), 最终得到的 K 的维度 是 (17,128)
# 将 k 的权重 分成 n_kv_heads=8 组
k_layer0 = model["layers.0.attention.wk.weight"]
k_layer0 = k_layer0.view(n_kv_heads, k_layer0.shape[0] // n_kv_heads, dim)
print(k_layer0.shape)
# 每组 k 权重 的维度是 (128, 4096)
k_layer0_head0 = k_layer0[0]
print(k_layer0_head0.shape)
# 矩阵乘,计算 k, (17, 4096)* (4096, 128)得到 k 的维度 (17, 128)
k_per_token = torch.matmul(token_embeddings, k_layer0_head0.T)
print(k_per_token.shape)
torch.Size([8, 128, 4096])
torch.Size([128, 4096])
torch.Size([17, 128])
对 K 进行旋转位置编码,编码后的 K 维度不变
k_per_token_split_into_pairs = k_per_token.float().view(k_per_token.shape[0], -1, 2)
print(k_per_token_split_into_pairs.shape)
k_per_token_as_complex_numbers = torch.view_as_complex(k_per_token_split_into_pairs)
print(k_per_token_as_complex_numbers.shape)
k_per_token_split_into_pairs_rotated = torch.view_as_real(k_per_token_as_complex_numbers * freqs_cis)
print(k_per_token_split_into_pairs_rotated.shape)
k_per_token_rotated = k_per_token_split_into_pairs_rotated.view(k_per_token.shape)
print(k_per_token_rotated.shape)
torch.Size([17, 64, 2])
torch.Size([17, 64])
torch.Size([17, 64, 2])
torch.Size([17, 128])
QK^T #
Q 和 K 的维度 都是 torch.Size([17, 128]), 通过矩阵乘得到 \(\frac{QK^T}{\sqrt{d_k}}\) 矩阵, 矩阵中的每个值都代表了对应位置 token 的 Q 和 K 的相关程度, 这就是 self-attention 的过程
qk_per_token = torch.matmul(q_per_token_rotated, k_per_token_rotated.T)/(head_dim)**0.5
qk_per_token.shape
Mask #
为了只保留每个 token 与他前面的[0…token]的注意力,将token位置之后的 QK 结果屏蔽,方法也很简单,创建一个上三角为负无穷、下三角和对角线为0的 mask 矩阵,然后与 \(\frac{QK^T}{\sqrt{d_k}}\) 相加即可
mask = torch.full((len(tokens), len(tokens)), float("-inf"), device=tokens.device)
mask = torch.triu(mask, diagonal=1)
qk_per_token_after_masking = qk_per_token + mask
print(mask)
tensor([[0., -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf],
[0., 0., -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf],
[0., 0., 0., -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf],
[0., 0., 0., 0., -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf],
[0., 0., 0., 0., 0., -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf],
[0., 0., 0., 0., 0., 0., -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf],
[0., 0., 0., 0., 0., 0., 0., -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf],
[0., 0., 0., 0., 0., 0., 0., 0., -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf],
[0., 0., 0., 0., 0., 0., 0., 0., 0., -inf, -inf, -inf, -inf, -inf, -inf, -inf, -inf],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., -inf, -inf, -inf, -inf, -inf, -inf, -inf],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., -inf, -inf, -inf, -inf, -inf, -inf],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., -inf, -inf, -inf, -inf, -inf],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., -inf, -inf, -inf, -inf],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., -inf, -inf, -inf],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., -inf, -inf],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., -inf],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]])
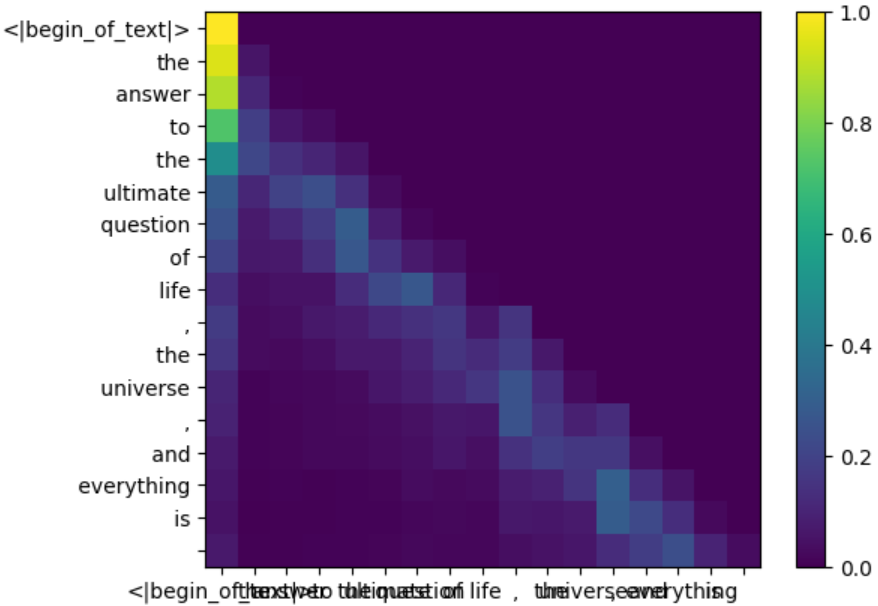
通过 heatmap 观察下 qk 在应用 mask 前后的变化
def display_qk_heatmap(qk_per_token):
_, ax = plt.subplots()
im = ax.imshow(qk_per_token.to(float).detach(), cmap='viridis')
ax.set_xticks(range(len(prompt_split_as_tokens)))
ax.set_yticks(range(len(prompt_split_as_tokens)))
ax.set_xticklabels(prompt_split_as_tokens)
ax.set_yticklabels(prompt_split_as_tokens)
ax.figure.colorbar(im, ax=ax)
display_qk_heatmap(qk_per_token)
display_qk_heatmap(qk_per_token_after_masking)
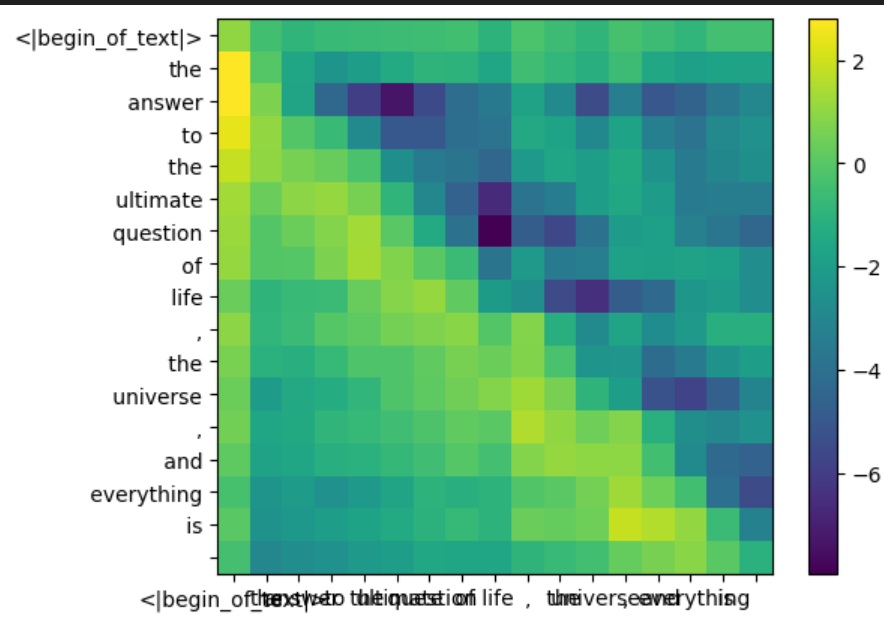
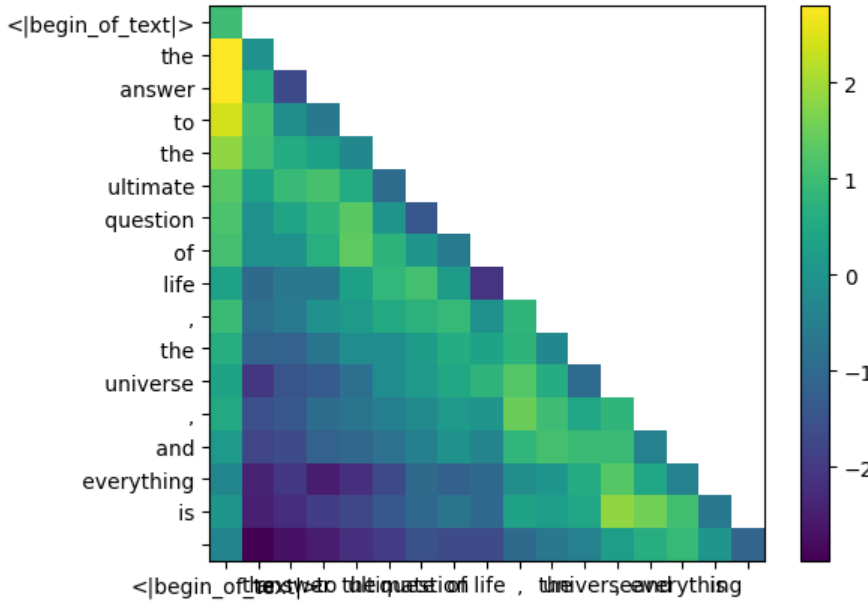
Softmax #
直接调用 pytorch 的 softmax kernel 计算 \(softmax(\frac{QK^T}{\sqrt{d_k}})\)
qk_per_token_after_masking_after_softmax = torch.nn.functional.softmax(qk_per_token_after_masking, dim=1).to(torch.bfloat16)
display_qk_heatmap(qk_per_token_after_masking_after_softmax)
Values #
value weight 跟 key weight 一样,也有 8 组, 每一组由 4 个 Query head 共享
v_layer0 = model["layers.0.attention.wv.weight"]
v_layer0 = v_layer0.view(n_kv_heads, v_layer0.shape[0] // n_kv_heads, dim)
print(v_layer0.shape)
v_layer0_head0 = v_layer0[0]
print(v_layer0_head0.shape)
v_per_token = torch.matmul(token_embeddings, v_layer0_head0.T)
print(v_per_token.shape)
torch.Size([8, 128, 4096])
torch.Size([128, 4096])
torch.Size([17, 128])
调用torch的矩阵乘算子 torch.matmul 计算 attention \(softmax(\frac{QK^T}{\sqrt{d_k}})V\)
qkv_attention = torch.matmul(qk_per_token_after_masking_after_softmax, v_per_token)
print(qkv_attention.shape)
torch.Size([17, 128])
至此,获得了第一个 attention layer 的 第一个 head 的 attention 结果,接下来直接通过迭代计算第一层的multi head attention, 因为 query 一共有 32 个 heads, 所以最终 的attention 结果 应该是 32 个 qkv_attention.shape 的 tensor
qkv_attention_store = []
for head in range(n_heads):
q_layer0_head = q_layer0[head]
k_layer0_head = k_layer0[head//4] # key weights are shared across 4 heads
v_layer0_head = v_layer0[head//4] # value weights are shared across 4 heads
q_per_token = torch.matmul(token_embeddings, q_layer0_head.T)
k_per_token = torch.matmul(token_embeddings, k_layer0_head.T)
v_per_token = torch.matmul(token_embeddings, v_layer0_head.T)
q_per_token_split_into_pairs = q_per_token.float().view(q_per_token.shape[0], -1, 2)
q_per_token_as_complex_numbers = torch.view_as_complex(q_per_token_split_into_pairs)
q_per_token_split_into_pairs_rotated = torch.view_as_real(q_per_token_as_complex_numbers * freqs_cis[:len(tokens)])
q_per_token_rotated = q_per_token_split_into_pairs_rotated.view(q_per_token.shape)
k_per_token_split_into_pairs = k_per_token.float().view(k_per_token.shape[0], -1, 2)
k_per_token_as_complex_numbers = torch.view_as_complex(k_per_token_split_into_pairs)
k_per_token_split_into_pairs_rotated = torch.view_as_real(k_per_token_as_complex_numbers * freqs_cis[:len(tokens)])
k_per_token_rotated = k_per_token_split_into_pairs_rotated.view(k_per_token.shape)
qk_per_token = torch.matmul(q_per_token_rotated, k_per_token_rotated.T)/(128)**0.5
mask = torch.full((len(tokens), len(tokens)), float("-inf"), device=tokens.device)
mask = torch.triu(mask, diagonal=1)
qk_per_token_after_masking = qk_per_token + mask
qk_per_token_after_masking_after_softmax = torch.nn.functional.softmax(qk_per_token_after_masking, dim=1).to(torch.bfloat16)
qkv_attention = torch.matmul(qk_per_token_after_masking_after_softmax, v_per_token)
qkv_attention = torch.matmul(qk_per_token_after_masking_after_softmax, v_per_token)
qkv_attention_store.append(qkv_attention)
print(len(qkv_attention_store)) # 32
把列表中的 tensor 拼接成一个高维度 tensor
stacked_qkv_attention = torch.cat(qkv_attention_store, dim=-1)
print(stacked_qkv_attention.shape) # torch.Size([17, 4096])
然后,经过 attention layer 的 wo.weight 对 attention 进行线性变换, 把 tensor 的维度从 torch.Size([4096, 4096]) 转换到最初的 torch.Size([17, 4096])
w_layer0 = model["layers.0.attention.wo.weight"]
print(w_layer0.shape) # torch.Size([4096, 4096])
embedding_delta = torch.matmul(stacked_qkv_attention, w_layer0.T)
print(embedding_delta.shape) # torch.Size([17, 4096])
最后,接一个 attention layer 最初输入(token_embeddings_unnormalized)的残差连接,就得到了第 1 个 attention layer 的 output,接下来输入到 FFN layer
embedding_after_edit = token_embeddings_unnormalized + embedding_delta
print(embedding_after_edit.shape) # torch.Size([17, 4096])
FFNLayer #
Llama3 使用了 SwiGLU feedforward network(FFN),FFN 有 三个 权重层,分别代表了 gate, up, down 三个线性变换。首先将 FFN 的输入归一化为 embedding_after_edit_normalized,然后调用 torch.matmul, torch.functional.F.silu 算子 将 embedding_after_edit_normalized 进行线性变换和激活,得到FFN的output: layer_0_embedding
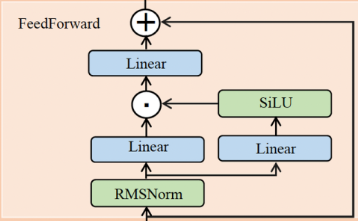
# norm
embedding_after_edit_normalized = rms_norm(embedding_after_edit, model["layers.0.ffn_norm.weight"])
embedding_after_edit_normalized.shape
w1 = model["layers.0.feed_forward.w1.weight"]
w2 = model["layers.0.feed_forward.w2.weight"]
w3 = model["layers.0.feed_forward.w3.weight"]
# ff
output_after_feedforward = torch.matmul(torch.functional.F.silu(torch.matmul(embedding_after_edit_normalized, w1.T)) * torch.matmul(embedding_after_edit_normalized, w3.T), w2.T)
print(output_after_feedforward.shape) # torch.Size([17, 4096])
# 残差
layer_0_embedding = embedding_after_edit+output_after_feedforward
print(layer_0_embedding.shape) # torch.Size([17, 4096])
至此,第 1 个 Decoderlayer 结束,
Total Steps #
Decoderlayer 的 output 作为 下一个 DecoderLayer 的 input,一共迭代 32 次, 然后在经过Norm 和 线性变化得到 logits(torch.Size([128256])),对 logit 施加 Softmax 分类(采用贪心策略,获取最高得分的token)即可得到 generated token,最后解码即可得到 生成的第一个 word
final_embedding = token_embeddings_unnormalized
for layer in range(n_layers):
qkv_attention_store = []
layer_embedding_norm = rms_norm(final_embedding, model[f"layers.{layer}.attention_norm.weight"])
q_layer = model[f"layers.{layer}.attention.wq.weight"]
q_layer = q_layer.view(n_heads, q_layer.shape[0] // n_heads, dim)
k_layer = model[f"layers.{layer}.attention.wk.weight"]
k_layer = k_layer.view(n_kv_heads, k_layer.shape[0] // n_kv_heads, dim)
v_layer = model[f"layers.{layer}.attention.wv.weight"]
v_layer = v_layer.view(n_kv_heads, v_layer.shape[0] // n_kv_heads, dim)
w_layer = model[f"layers.{layer}.attention.wo.weight"]
for head in range(n_heads):
q_layer_head = q_layer[head]
k_layer_head = k_layer[head//4]
v_layer_head = v_layer[head//4]
q_per_token = torch.matmul(layer_embedding_norm, q_layer_head.T)
k_per_token = torch.matmul(layer_embedding_norm, k_layer_head.T)
v_per_token = torch.matmul(layer_embedding_norm, v_layer_head.T)
q_per_token_split_into_pairs = q_per_token.float().view(q_per_token.shape[0], -1, 2)
q_per_token_as_complex_numbers = torch.view_as_complex(q_per_token_split_into_pairs)
q_per_token_split_into_pairs_rotated = torch.view_as_real(q_per_token_as_complex_numbers * freqs_cis)
q_per_token_rotated = q_per_token_split_into_pairs_rotated.view(q_per_token.shape)
k_per_token_split_into_pairs = k_per_token.float().view(k_per_token.shape[0], -1, 2)
k_per_token_as_complex_numbers = torch.view_as_complex(k_per_token_split_into_pairs)
k_per_token_split_into_pairs_rotated = torch.view_as_real(k_per_token_as_complex_numbers * freqs_cis)
k_per_token_rotated = k_per_token_split_into_pairs_rotated.view(k_per_token.shape)
qk_per_token = torch.matmul(q_per_token_rotated, k_per_token_rotated.T)/(128)**0.5
mask = torch.full((len(token_embeddings_unnormalized), len(token_embeddings_unnormalized)), float("-inf"))
mask = torch.triu(mask, diagonal=1)
qk_per_token_after_masking = qk_per_token + mask
qk_per_token_after_masking_after_softmax = torch.nn.functional.softmax(qk_per_token_after_masking, dim=1).to(torch.bfloat16)
qkv_attention = torch.matmul(qk_per_token_after_masking_after_softmax, v_per_token)
qkv_attention_store.append(qkv_attention)
stacked_qkv_attention = torch.cat(qkv_attention_store, dim=-1)
w_layer = model[f"layers.{layer}.attention.wo.weight"]
embedding_delta = torch.matmul(stacked_qkv_attention, w_layer.T)
embedding_after_edit = final_embedding + embedding_delta
embedding_after_edit_normalized = rms_norm(embedding_after_edit, model[f"layers.{layer}.ffn_norm.weight"])
w1 = model[f"layers.{layer}.feed_forward.w1.weight"]
w2 = model[f"layers.{layer}.feed_forward.w2.weight"]
w3 = model[f"layers.{layer}.feed_forward.w3.weight"]
output_after_feedforward = torch.matmul(torch.functional.F.silu(torch.matmul(embedding_after_edit_normalized, w1.T)) * torch.matmul(embedding_after_edit_normalized, w3.T), w2.T)
final_embedding = embedding_after_edit+output_after_feedforward
final_embedding = rms_norm(final_embedding, model["norm.weight"])
print(final_embedding.shape) # torch.Size([17, 4096])
print(model["output.weight"].shape) # torch.Size([128256, 4096])
logits = torch.matmul(final_embedding[-1], model["output.weight"].T)
print(logits.shape) # torch.Size([128256])
next_token = torch.argmax(logits, dim=-1) # softmax
print(next_token) # tensor(2983)
print(tokenizer.decode([next_token.item()])) # 42
至此,我们得到了第一个生成的 token,它与最初的 prompt token 组成新的 input 用于生成下一个token
Summary #
本文介绍了如何一步步得使用 python 和 pytorch 加载 llama3 并进行文本生成。重点介绍了 Llama3模型结构,DecoderLayer的实现,包括其中的 AttentionLayer 和 FFNLayer,并深入探讨了模型的各层参数和维度。
本文的 AttentionLayer 采用了标准的 multi-head-attention,未体现 KVCache 和 FlashAttention、PagedAttention等优化,这些优化技术可参考我的这个系列文章: Attention and Optimization
Reference: