CPU 与 GPU 的不同 #
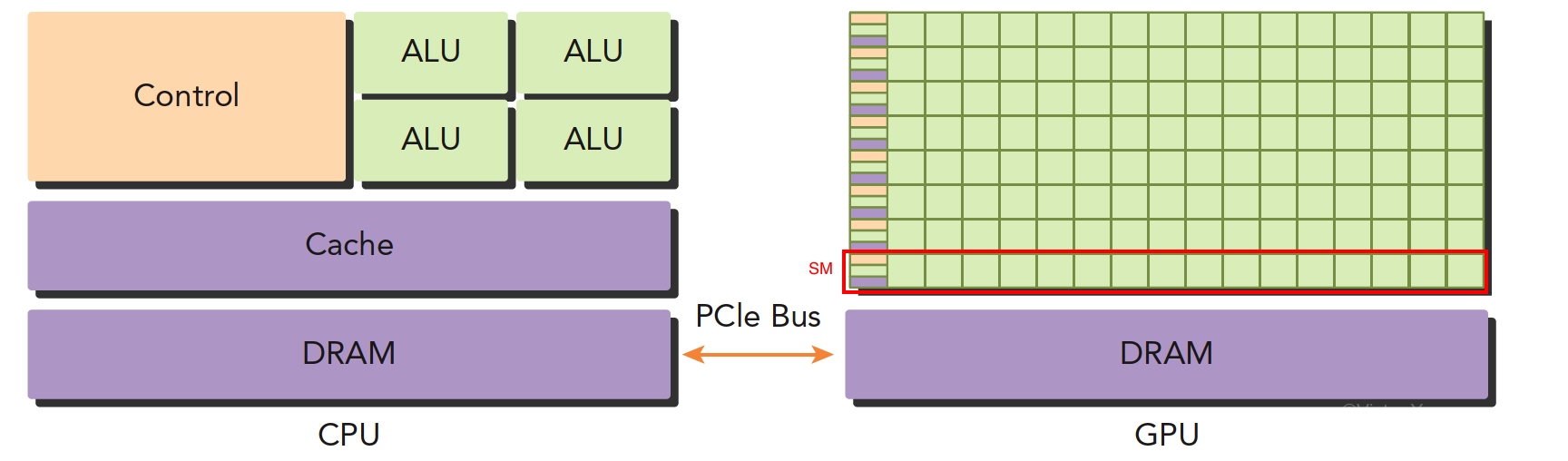
- CPU,4个 ALU,主要负责逻辑计算,1个控制单元 Control,1个 DRAM,1个 Cache
- GPU,绿色小方块看作 ALU,红色框看作一个 SM,SM 中的多个 ALU share 一个Control 和 Cache,SM 可以看作一个多核 CPU,但是 ALU 更多,control 更少,也就是算力提升,控制力减弱
所以,CPU 适合控制逻辑复杂的任务,GPU 适合逻辑简单、数据量大、计算量大的任务。
GPU, CUDA, AI Framework 的关系 #
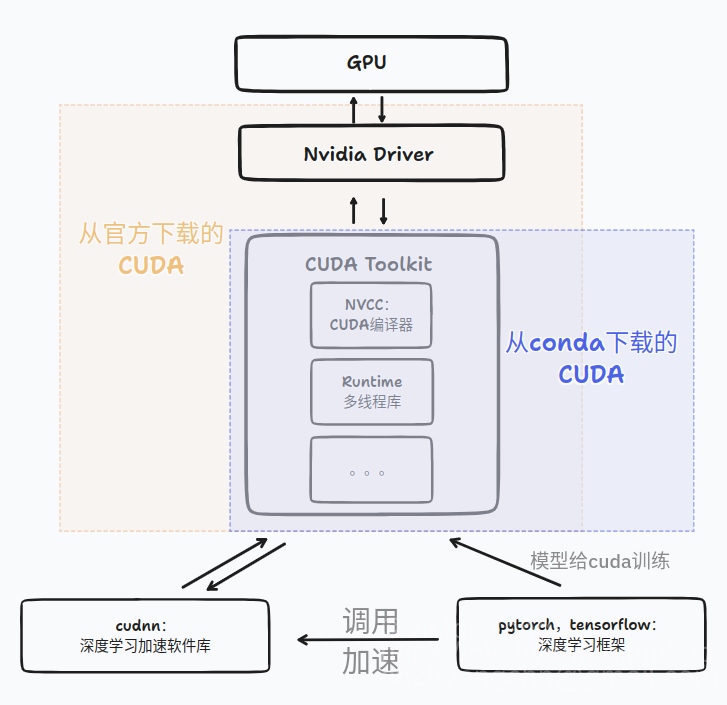
Reference:
GPU 内部结构 #
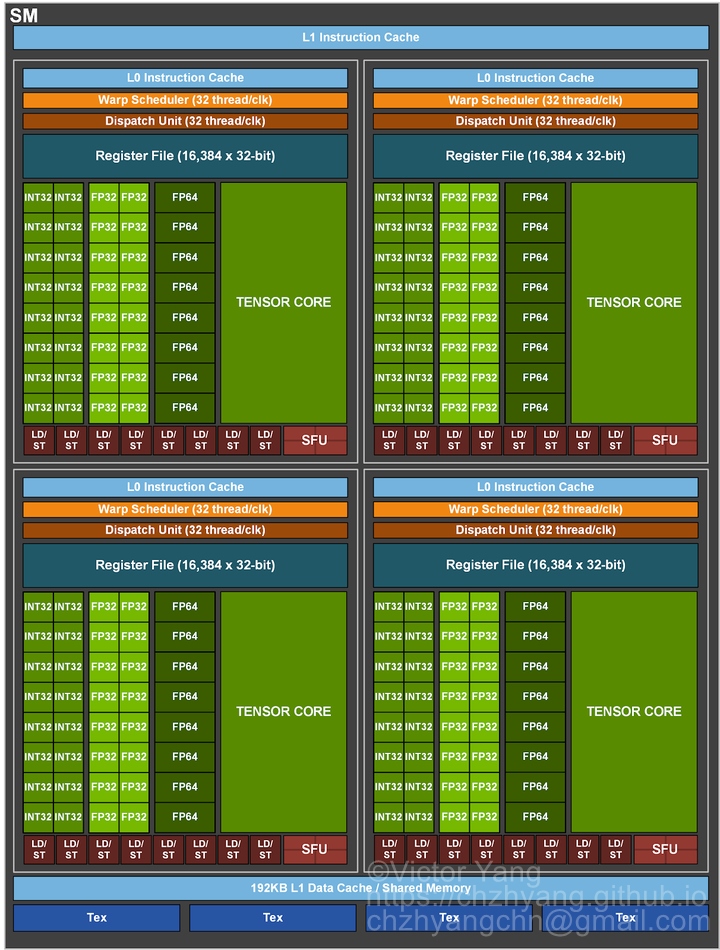
每一个 SM 有自己的 Wrap scheduler 、寄存器(Register)、指令缓存、L1缓存、共享内存。
A100 中每个 SM 包括 4 个 SM partition(SMP),里边绿色的就是 Streaming Processor(SP),也叫 CUDA cores,它们是实际执行计算的基本单元。
所有的 SM 共享 L2 缓存。整个 GPU 内存结构如下图所示
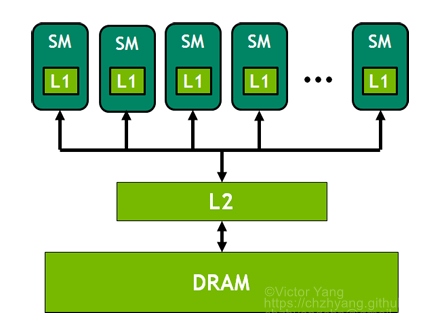
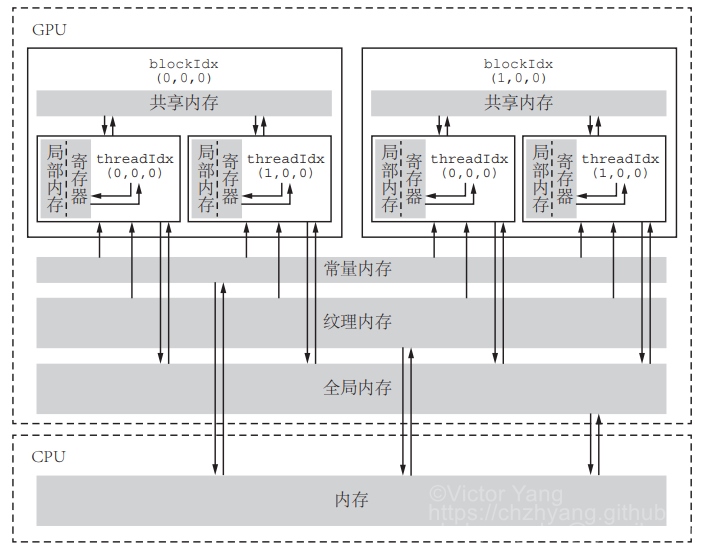
GPU 内存结构 #
按照存储功能进行细分,GPU 内存可以分为:局部内存(local memory)、全局内存(global memory)、常量内存(constant memory)、共享内存(shared memory)、寄存器(register)、L1/L2 缓存等。
其中全局内存、局部内存、常量内存都是片下内存(off-chip),储存在 HBM 上。所以 HBM 的大部分作为全局内存。
-
on-chip:L1/L2 cache:多级缓存,在 GPU 芯片内部
-
off-chip:GPU DRAM/HBM, global memory
-
L2 缓存可以被所有 SM 访问,速度比全局内存快。Flash attention 的思路就是尽可能地利用 L2 缓存,减少 HBM 的数据读写时间
-
L1 缓存用于存储 SM 内的数据,被 SM 内的 CUDA cores 共享,但是跨 SM 之间的 L1 不能相互访问
-
局部内存 (local memory) 是线程独享的内存资源,线程之间不可以相互访问。局部内存属于off-chip,所以访问速度跟全局内存一样。它主要是用来应对寄存器不足时的场景,即在线程申请的变量超过可用的寄存器大小时,nvcc 会自动将一部数据放置到片下内存里。
-
寄存器(register)是线程能独立访问的资源,它是片上(on chip)存储,用来存储一些线程的暂存数据。寄存器的速度是访问中最快的,但是它的容量较小,只有几百甚至几十 KB,而且要被许多线程均分
-
共享内存(shared memory) 是一种在线程块内能访问的内存,是片上(on chip)存储,访问速度较快。共享内存主要是缓存一些需要反复读写的数据。共享内存与 L1 缓存的位置、速度极其类似,区别在于共享内存的控制与生命周期管理与 L1 不同:共享内存受用户控制,L1 受系统控制。共享内存更利于线程块之间数据交互。
-
常量内存(constant memory)是片下(off chip)存储,但是通过特殊的常量内存缓存(constant cache)进行缓存读取,它是只读内存。常量内存主要是解决一个 warp scheduler 内多个线程访问相同数据时速度太慢的问题。假设所有线程都需要访问一个 constant_A 的常量,在存储介质上 constant_A 的数据只保存了一份,而内存的物理读取方式决定了多个线程不能在同一时刻读取到该变量,所以会出现先后访问的问题,这样使得并行计算的线程出现了运算时差。常量内存正是解决这样的问题而设置的,它有对应的 cache 位置产生多个副本,让线程访问时不存在冲突,从而保证并行度。
| 内存类型 | 物理位置 | 访问权限 | 可见范围 | 生命周期 |
|---|---|---|---|---|
| 全局内存 | 在芯片外 | 可读可写 | 所有线程和主机端 | 由主机分配与释放 |
| 常量内存 | 在芯片外 | 仅可读 | 所有线程和主机端 | 由主机分配与释放 |
| 纹理和表面内存 | 在芯片外 | 一般仅可读 | 所有线程和主机端 | 由主机分配与释放 |
| 寄存器内存 | 在芯片内 | 可读可写 | 单个线程 | 所在线程 |
| 局部内存 | 在芯片外 | 可读可写 | 单个线程 | 所在线程 |
| 共享内存 | 在芯片内 | 可读可写 | 单个线程块 | 所在线程块 |
“全局内存”(global memory)的含义是核函数中的所有线程都能够访问其中的数 据. 一般用 cudaMalloc 函数为全局内存变量分配设备内存,用 cudaMemcpy(h_z, d_z, M, cudaMemcpyDeviceToHost) 或 cudaMemcpyDeviceToDevice 拷贝内存。在处理逻辑上的两维或三维问题时,可以用 cudaMallocPitch 和 cudaMalloc3D 函数分配内存,用 cudaMemcpy2D 和 cudaMemcpy3D 复制数据,释放时依然用 cudaFree 函数。
静态全局内存变量: 所占内存数量是在编译期间就确定的。而且,这样的静态全局内存变量必须在所有主机与设备函数外部定义,所以是一种“全局的静态全局内存变量”。在核函数中,可直接对静态全局内存变量进行访问,并不需要将它们以参数的形式传给核 函数。静态全局内存变量由以下方式在任何函数外部定义:
__device__ T x; // 单个变量
__device__ T y[N]; // 固定长度的数组
不可在主机函数中直接访问静态全局内存变量,但可以用 cudaMemcpyToSymbol 函 数和 cudaMemcpyFromSymbol 函数在静态全局内存与主机内存之间传输数据。
常量内存(constant memory)是有常量缓存的全局内存,数量有限,一共仅有 64 KB。它的可见范围和生命周期与全局内存一样。常量内存仅可读、不可写。访问速度比全局内存高,但得到高访问速度的前提是一个线程束中的线程(一个线程块中相邻的 32 个线程)要读取相同的常量内存数据。常量内存的方法是在核函数外面用 constant 定义变量,用 cudaMemcpyToSymbol 将数据从主机端复制到设备的常量内存后 供核函数使用
在核函数中定义的不加任何限定符的变量一般来说就存放于寄存器(register)中。核函数中定义的不加任何限定符的数组有可能存放于寄存器中,但也有可能存放于局部内存中。如 gridDim、blockDim、blockIdx、threadIdx 及 warpSize 都保存在特殊的寄存器中。这里的 n 就是一个寄存器变量:
const int n = blockDim.x * blockIdx.x + threadIdx.x;
寄存器变量仅仅被一个线程可见。
局部内存: 寄存器中放不下的变量,以及索引值不能在编译时就确定的数组,都有可能放在局部内存中。
共享内存和寄存器类似,存在于芯片上,具有仅次于寄存器的读写速度,数量也有限。共享内存对整个线程块可见,主要作用是减少对全局内存的访问。
SM 的构成 #
一个GPU是由多个SM(Streaming Multiprocessor)构成的。一个SM包含如下资源:
- 一定数量的寄存器
- 一定数量的共享内存
- 常量内存的缓存
- 纹理和表面内存的缓存
- L1缓存
- 两个(计算能力6.0)或4个(其他计算能力)线程束调度器(warp scheduler)用于不同线程的上下文之间迅速地切换,以及为准备就绪的线程束发出执行指令
- 执行核心,包括:
- 若干整型数运算的核心(INT32)
- 若干单精度浮点数运算的核心(FP32)
- 若干双精度浮点数运算的核心(FP64)
- 若干单精度浮点数超越函数(transcendental functions)的特殊函数单元(special function units, SFUs)
- 若干混合精度的张量核心(tensor cores,由伏特架构引入,适用于机器学习中的低精度矩阵计算)
SM的占有率: 在并行规模足够大(即核函数执行配置中定义的总线程数足够多)的前提下分几种情况来分析SM的理论占有率:
(1) 寄存器和共享内存使用量很小的情况。此时,SM的占有率完全由执行配置中的线程块大小决定。关于线程块大小,读者也许注意到我们之前一直用128。这是因为,SM中线程的执行是以线程束为单位的,所以最好将线程块大小取为线程束大小(32个线程)的整数倍。例如,假设将线程块大小定义为100,那么一个线程块中将有3个完整的线程束(一共96个线程)和一个不完整的线程束(只有4个线程)。在执行核函数中的指令时,不完整的线程束花的时间和完整的线程束花费的时间一样,这就无形中浪费了计算资源。所以,建议将线程块大小取为32的整数倍。在该前提下,任何不小于$N_t/N_b$而且能整除$N_t$的线程块大小都能得到100%的占有率;线程块大小不小于64时其他架构能获得100%的占有率。根据我们列出的数据,线程块大小不小于128时开普勒架构能获得100%的占有率;线程块大小不小于64时其他架构能获得100%的占有率。作者近几年都用一块开普勒架构的Tesla K40开发程序,所以习惯了在一般情况下用128的线程块大小。
(2) 有限寄存器数量对占有率的约束情况。我们只针对第三节中列出的几个计算能力进行分析,读者可以类似地分析其他未列出的计算能力。对于第三节中列出的所有计算能力,一个SM最多能使用的寄存器个数为64K(64 x 1024)。除图灵架构外,如果我们希望在一个SM中驻留最多的线程(2048个),核函数中的每个线程最多只能用32个寄存器。当每个线程所用寄存器个数大于64时,SM的占有率将小于50%;当每个线程所用寄存器个数大于128时,SM的占有率将小于25%。对于图灵架构,同样的占有率允许使用更多的寄存器。
(3) 有限的共享内存对占有率的约束清理。因为共享内存的数量随着计算能力的上升没有显著的变化规律,所以我们这里仅对计算能力3.5进行分析,对其他计算能力可以类似地分析。如果线程块大小为128,那么每个SM要激活16个线程块才能有2048个线程,达到100%的占有率。此时,一个线程块最多能使用3KB的共享内存。在不改变线程块大小的情况下,要达到50%的占有率,一个线程块最多能使用6KB的共享内存;要达到25%的占有率,一个线程块最多能使用12KB的共享内存。如果一个线程块使用了超过48KB的共享内存,会直接导致核函数无法允许。对其他线程块大小可进行类似的分析。
在 CUDA 工具箱中,有一个 CUDA_Occupancy_Calculator.xls,可用来计算各种情况下的 SM 占有率。
## 重要的计算能力技术指标
SM 寄存器数上限、单个线程块寄存器数上限、单个线程寄存器数上限、SM 共享内存上限、单个线程块共享内存上限、SM 线程块上限、 SM 线程数上限
代码中查询技术指标:
```c++
#include "error.cuh" //CHECK
#include <cstdio>
int main(int argc, char *argv[])
{
int device_id = 0;
if (argc > 1) device_id = atoi(argv[1]);
CHECK(cudaSetDevice(device_id));
cudaDeviceProp prop;
CHECK(cudaGetDeviceProperties(&prop, device_id));
printf("Device id: %d\n",
device_id);
printf("Device name: %s\n",
prop.name);
printf("Compute capability: %d.%d\n",
prop.major, prop.minor);
printf("Amount of global memory: %g GB\n",
prop.totalGlobalMem / (1024.0 * 1024 * 1024));
printf("Amount of constant memory: %g KB\n",
prop.totalConstMem / 1024.0);
printf("Maximum grid size: %d %d %d\n",
prop.maxGridSize[0],
prop.maxGridSize[1], prop.maxGridSize[2]);
printf("Maximum block size: %d %d %d\n",
prop.maxThreadsDim[0], prop.maxThreadsDim[1],
prop.maxThreadsDim[2]);
printf("Number of SMs: %d\n",
prop.multiProcessorCount);
printf("Maximum amount of shared memory per block: %g KB\n",
prop.sharedMemPerBlock / 1024.0);
printf("Maximum amount of shared memory per SM: %g KB\n",
prop.sharedMemPerMultiprocessor / 1024.0);
printf("Maximum number of registers per block: %d K\n",
prop.regsPerBlock / 1024);
printf("Maximum number of registers per SM: %d K\n",
prop.regsPerMultiprocessor / 1024);
printf("Maximum number of threads per block: %d\n",
prop.maxThreadsPerBlock);
printf("Maximum number of threads per SM: %d\n",
prop.maxThreadsPerMultiProcessor);
}
## Tensor Core
CUDA core 和 Tensor core 的区别:
- Tensor core 是在 Volta 以及之后的架构中才有的, 相比于CUDA core,它可以提供更高效的运算。
- 每个 GPU clock,CUDA core 可以进行一次单精度乘加运算,即:in fp32: x += y * z。
- 每个 GPU clock,Tensor core 可以完成 4 × 4 的混合精度矩阵乘加 (matrix multiply-accumulate, MMA):D=A * B + C,其中 A、B、C、D 都是 4 × 4 矩阵。A 和 B是 FP16 矩阵,而累加矩阵 C 和 D 可以是 FP16 或 FP32 矩阵(FP16/FP16 或 FP16/FP32 两种模式。所以每个 GPU clock,Tensor core 可以执行 64 个浮点 FMA 混合精度运算(4 × 4 × 4)。
- Turing 架构中新增了 INT8/INT32, INT4/INT32, INT1/INT32 等模式

V100 中,一个 SM 中有 8 个 Tensor core,每个 GPU clock 共可以执行 1024 个浮点运算(64 × 8 × 2,乘以 2 因为乘加是两个浮点运算)
Reference:
- [TENSOR CORE DL PERFORMANCE GUIDE](https://link.zhihu.com/?target=https%3A//developer.download.nvidia.com/video/gputechconf/gtc/2019/presentation/s9926-tensor-core-performance-the-ultimate-guide.pdf)
- [GPU内存概念浅析](https://www.cnblogs.com/ArsenalfanInECNU/p/18021724)