Kernel Function #
gridDim
gridDim.x、gridDim.y、gridDim.z分别表示 grid 各个维度的大小
blockDim
blockDim.x、blockDim.y、blockDim.z分别表示 block 各个维度的大小
blockIdx
blockIdx.x、blockIdx.y、blockIdx.z分别表示当前 block 在 grid 中的坐标
threadIdx
threadIdx.x、threadIdx.y、threadIdx.z分别表示当前 thread 在 block 的坐标
grid 里总的线程个数 N = gridDim.x * gridDim.y * gridDim.z * blockDim.x * blockDim.y * blockDim.z
通过 blockIdx.x、blockIdx.y、blockIdx.z、threadIdx.x、threadIdx.y、threadIdx.z 可以定位一个线程的坐标。
主流架构一个block三个唯独的设置最多为(1024, 1024, 64),同时总线程数最多只能有 1024 个。
将所有的线程排成一个序列,序列号为 0 , 1 , 2 , … , N ,如何找到当前 thread 的序列号 ?
- 先找到该thread所在的 block的序号 blockId = blockIdx.x + blockIdx.ygridDim.x + blockIdx.zgridDim.x*gridDim.y
- 然后找到当前 thread 在 block 中的序号 threadId = threadIdx.x + threadIdx.yblockDim.x + threadIdx.zblockDim.x*blockDim.y
- 计算一个 block 中一共有多少个 thread, M = blockDim.xblockDim.yblockDim.z
- 求得当前的线程的序列号 idx = threadId + M*blockId
Device function #
kernel 可以调用不带执行配置的自定义函数,这样的自定义函数称为设备函数(devicefunction)。它是在设备中执行,并在设备中被调用的。与之相比,核函数是在设备中执行,但在主机端被调用的。
double __device__ add1_device(const double x, const double y)
{
return (x + y);
}
void __global__ add1(const double *x, const double *y, double *z,
const int N)
{
const int n = blockDim.x * blockIdx.x + threadIdx.x;
if (n < N)
{
z[n] = add1_device(x[n], y[n]);
}
}
CUDA 常用的函数 #
同步函数 __syncthreads: 只能用在核函数中 __syncthreads(),该函数可保证一个线程块中的所有线程(或者说所有线程束)在执行该语句后面的语句之前都完全执行了该语句前面的语句。然而,该函数只是针对同一个线程块中的线程的,不同线程块中线程的执行次序依然是不确定的。
CUDA Event Record #
在 C++ 中,有多种可以对一段代码进行计时的方法,如使用 GCC 的 clock 函数和与头文件
CUDA 提供了一种基于 CUDA 事件(CUDA event)的计时方式,可用来给一段 CUDA 代码(可能包含了主机代码和设备代码)计时。下面的例子涵盖了计时的基本流程:
//creat
CHECK(cudaEventCreate(&start));
CHECK(cudaEventCreate(&stop));
//record
CHECK(cudaEventRecord(start));
cudaEvent_t start, stop;
cudaEventQuery(start)
//+需要计时的代码块
CHECK(cudaEventRecord(stop));
CHECK(cudaEventSynchronize(stop));
float elapsed_time;
//compute
CHECK(cudaEventElapsedTime(&elapsed_time, start, stop));
printf("Time = %g ms.\n", elapsed_time);
//clean
CHECK(cudaEventDestroy(start));
CHECK(cudaEventDestroy(stop));
Steps of CUDA Program #
- Config GPU(device),
cudaSetDevice() - Allocate device memory,
cudaMalloc(),cudaMallocManaged() - Allocate CPU(Host) memory
- Copy data from host to device,
cudaMemcpy() - Run kernel on device
- Copy result from device to host,
cudaMemcpy() - Print result on host
- Release host and device memory,
cudaFree(),free()
CPU is always called host, the GPU is called device
C Example:
// file: sample.cu
#include<stdint.h>
#include<cuda.h>
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
// This is a sample CUDA kernel, called on host and execte on device
__global__ void add(float* a)
{
a[threadIdx.x] = 1;
}
int main(int argc, char** argv)
{
// 1. Set device
cudaSetDevice(0);
// 2. Allocate device memory
float* dx;
cudaMalloc((void**)&dx, 16 * sizeof(float));
// 3. Allocate host memory
float hx[16] = { 0 };
// 4. Copy data from host to device
cudaMemcpy(dx, hx, 16 * sizeof(float), cudaMemcpyHostToDevice);
// 5. Run kernel on device
add << <1, 16 >> > (dx);
// 6. Copy result from device to host
cudaMemcpy(hx, dx, 16 * sizeof(float), cudaMemcpyDeviceToHost);
// 7. Print result on host
for (int i = 0; i < 16; i++)
{
printf("%f \n", hx[i]);
}
8. Release host and device memory
cudaFree(dx);
free(hx);
//cudaDeviceReset();
return 0;
}
使用nvcc编译,然后运行
nvcc sample.cu - o sample
./sample
CUDA 提供了统一内存: gpu和cpu可访问的单一内存空间. 调用
cudaMallocManaged(),它返回一个指针,从host code或device code都可以访问。要释放数据,只需将指针传递给cudaFree()。
CUDA Kernel and Parrallel Computing #
前置知识: 理解 GPU 结构, Grid, Block, Thread 这几个逻辑概念之间的关系
CUDA kernel 的编程模型
[Todo] Dim and size detail
调用kernel: add << <blockNumber, threadNumber >> > (dx);
编写kernel:
- 用关键字描述符
__global__声明kernel:__global__ void add(){} - 调用 kernel 时的参数
<<<blockNumber per grid, threadNumber per block>>>决定了共有TotalThreadNum = blockNumber * threadNumber个线程可以并行执行任务 - kernel 内的每一次迭代,意味着
TotalThreadNum个线程并行执行了一次循环体中的任务(即每个线程完成对一份数据的处理),也就是每次迭代能处理TotalThreadNum份数据,TotalThreadNum也等价于跨步(stride)的大小 - kernel 中
threadIdx.x代表 the index of the thread within the block,blockDim.x代表 the size of block(number of threads in block(假设 这里的 grid 和 block 的 dim 只有一维) - kernel 内
threadIdx.x和blockIdx.x的组合对应线程的唯一标识
以add_3这个 kernel 为例,可以用 index = blockIdx.x * blockDim.x + threadIdx.x 获得当前线程的要处理的数据的数组下标(见下图),
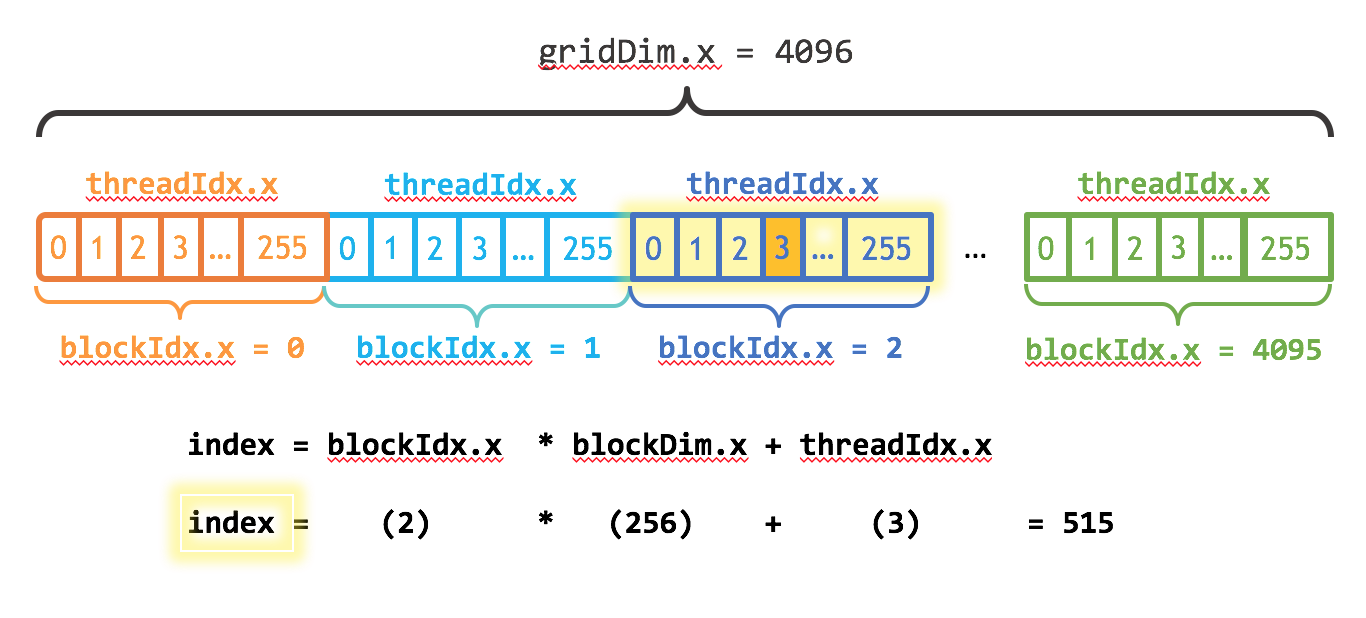
__global__
void add_3(int n, float *x, float *y)
{
int index = blockIdx.x * blockDim.x + threadIdx.x;
// stride为grid的线程总数:blockDim.x*gridDim.x
int stride = blockDim.x * gridDim.x;
for (int i = index; i < n; i += stride)
y[i] = x[i] + y[i];
}
Kernel examples(下面的 C++ Example)
- 1个block,1个线程: add_1()
- 1个block,多个线程: add_2()
- 多个block,多个线程: add_3()
多个block,多个线程也称为网格跨步循环,其中每次循环的跨步(stride)为 grid 的线程总数: stride = blockDim.x * gridDim.x
C++ Example:
// file: add.cu
#include <iostream>
#include <math.h>
// Kernel function to add the elements of two arrays
// single thread
__global__
void add_1(int n, float *x, float *y)
{
for (int i = 0; i < n; i++)
y[i] = x[i] + y[i];
}
// single block, multi threads
__global__
void add_2(int n, float *x, float *y)
{
int index = threadIdx.x;
int stride = blockDim.x;
for (int i = index; i < n; i += stride)
y[i] = x[i] + y[i];
}
// multi block, multi threads
// 网格跨步(stride)循环
__global__
void add_3(int n, float *x, float *y)
{
int index = blockIdx.x * blockDim.x + threadIdx.x;
// stride为grid的线程总数:blockDim.x*gridDim.x
int stride = blockDim.x * gridDim.x;
for (int i = index; i < n; i += stride)
y[i] = x[i] + y[i];
}
int main(void)
{
int N = 1<<20;
float *x, *y;
// Allocate Unified Memory – accessible from CPU or GPU
cudaMallocManaged(&x, N*sizeof(float));
cudaMallocManaged(&y, N*sizeof(float));
// initialize x and y arrays on the host
for (int i = 0; i < N; i++) {
x[i] = 1.0f;
y[i] = 2.0f;
}
// Run kernel on 1M elements on the GPU
// Just run with single thread :)
add_1<<<1, 1>>>(N, x, y);
// Run with 1 block and multi threads
add_2<<<1, 256>>>(N, x, y);
// Run with multi block and multi threads
int blockSize = 256;//并行线程数量
int numBlocks = (N + blockSize - 1) / blockSize;//线程块数量
add_3<<<numBlocks, blockSize>>>(N, x, y);
// Wait for GPU to finish before accessing on host
cudaDeviceSynchronize();
// Check for errors (all values should be 3.0f)
float maxError = 0.0f;
for (int i = 0; i < N; i++)
maxError = fmax(maxError, fabs(y[i]-3.0f));
std::cout << "Max error: " << maxError << std::endl;
// Free memory
cudaFree(x);
cudaFree(y);
return 0;
}
CUDA Code Profiling #
nvprof是CUDA工具包附带的命令行GPU分析器
Reference: