Background #
Autoregressive generation can only sample and generate new tokens one by one, and the generation process of each new token depends on all the previous tokens in that sequence, specifically their key and value vectors, which are often cached for generating future tokens, known as KV cache.
The generation computation in LLM inference can be decomposed into two phases:
- Prefill phase(prompt)
- Decode phase(autoregressive generation)
The compute utilization in serving LLMs can be improved by batching multiple requests, but the number of requests that can be batched together is still constrained by GPU memory capacity, particularly the space allocated to store the KV cache. In other words, the LLM serving system’s throughput is memory-bound.
There are serveral KV cache memory management challenges:
- Longer sequence length and larger batch size lead to large KV cache
- Sheduling problem caused by dynamic sequence length(input, output)
- GPU memory limitation
- Memory wastes
- Hard to share memory
Existing LLM serving systems always statically allocate a chunk of memory for a request based on the request’s maximum possible sequence length(chunk pre-allocation), irrespective of the actual input or eventual output length of the request.
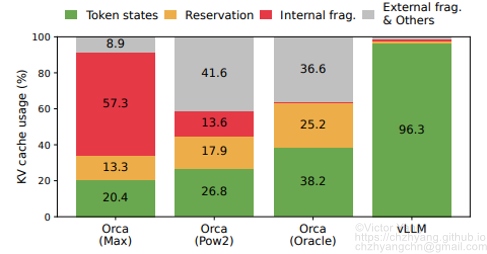
There are three primary sources of memory wastes(Fig. 1) in chunk pre-allocation scheme of existing systems:
- Reserved slots for future tokens
- Internal fragmentation due to over-provisioning for potential maximum sequence lengths
- External fragmentation from the memory allocator like the buddy allocator

Fig. 2 shows the average percentage of memory wastes in experiments, revealing the actual effective memory in previous systems can be as low as 20.4%.
vLLM #
To tackle KV cache memory management challenges, Woosuk Kwon, Zhuohan Li, etc. developed a new attention algorithm, PagedAttention, and build an LLM serving engine: vLLM.
vLLM is a LLM inference and serving lib designed for throughput, evolving fast, best performance , it provides efficient memory management for LLM serving with paged attention.The architecture of vLLM is shown in Fig. 3.
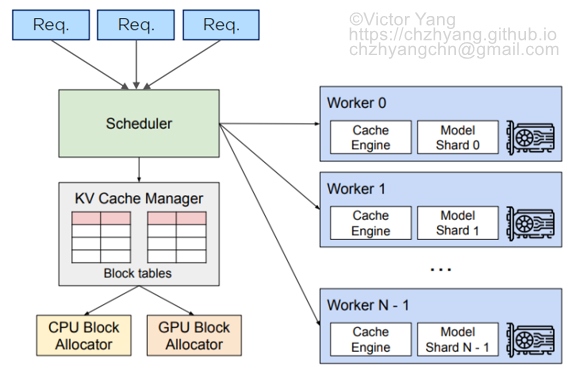
vLLM adopts a centralized scheduler to coordinate the execution of distributed GPU workers. The KV cache manager effectively manages the KV cache in PagedAttention. Specifically, the KV cache manager manages the physical KV cache memory on the GPU workers through the instructions sent by the centralized scheduler.
The key technique of vLLM include:
- Continues batching
- Paged Attention
- Optimized CUDA kernels
Continuous Batching #
As you know, Memory IO takes longer time in decoding, and the bottleneck is batch size, batching is a way to improve throughput. The naive batching(static batching, Fig.4) is batch-level scheduling(Fig 3), there are serveral disadvantages:
- Token padding
- Inefficient GPU usage
- High response latency
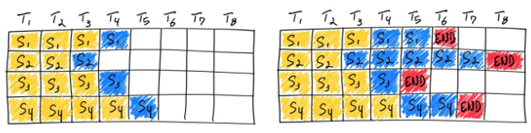
The continuous batching(Seq-level scheduling, Fig. 5):
- No token padding
- Without waiting the entire batch, reduce latency
- Improve GPU utilization
PagedAttention #
Inspired by virtual memory and paging in OS, vLLM partitions the KV cache of each sequence into KV blocks(allocation unit). Each block contains the key and value vectors for a fixed number of tokens, so that:
- KV blocks will be stored in non-contiguous physical memory
- Mapping Logical KV cache with physical blocks using a block table(per seq)
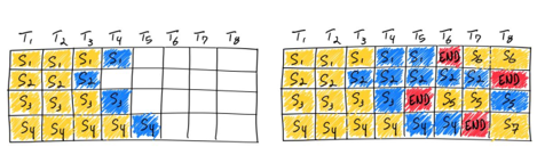
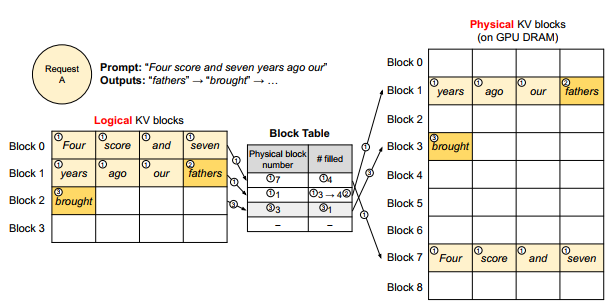
Fig. 6 demonstrates how vLLM executes PagedAttention and manages the memory during the decoding process of a single sequence:
- Generate 1st token(prefill): vLLM reserves only the necessary KV blocks to accommodate the KV cache generated during prompt computation. The prompt has 7 tokens, so vLLM maps the first 2 logical KV blocks (0 and 1) to 2 physical KV blocks (7 and 1, respectively). In prefill step, vLLM generates the KV cache of the prompts and the first output token with a conventional self-attention algorithm. vLLM then stores the KV cache of the first 4 tokens in logical block 0 and the following 3 tokens in logical block 1. The remaining slot is reserved for the subsequent autoregressive generation phase
- Generate second token(decode): In step 1, vLLM generates the new token with the PagedAttention algorithm on physical blocks 7 and 1. Since one slot remains available in the last logical block, the newly generated KV cache is stored there, and the block table’s filled record is updated
- Generate third token(decode): In step 2, as the last logical block is full, vLLM stores the newly generated KV cache in a new logical block; vLLM allocates a new physical block (physical block 3) for it and stores this mapping in the block table
PagedAttention has two Advantages:
- High memory utilization, as in Fig. 2, vLLM utilizes up to 96.3% KV cache memory
- Memory sharing(parallel sampling)
More details of paged attention, especailly it’s CUDA kernel, please refer to my another blog: Paged Attention
Reference #
- vLLM blog
- vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention
- Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. 2022. Flashattention: Fast and memory-efficient exact attention with io-awareness. Advances in Neural Information Processing Systems 35 (2022), 16344–16359