vLLM #
vLLM是吞吐性能卓越的大模型推理框架,PagedAttention是vLLM最大的创新点: Efficient Memory Management for Large Language Model Serving with PagedAttention
vLLM中的attention计算,在推理的prefill阶段, 使用第三方库xformers的优化实现,decoding阶段使用 CUDA kernel 实现(csrc/attention/attention_kernels.cu,大约800多行)。
Attention计算时使用页式管理 KV Cache 来提高内存利用率,进而提高吞吐量。
Paged Attention(PA) #
vLLM中有两个版本的 PA,其中:
- V1 源于 FasterTransformers 的 MHA,适用于 len(seq) < 8192 或 num_seqs * num_heads > 512 的情况。
- V2 参考了 Flash Decoding方式,对 sequence 的维度进行切分来增加并行粒度
Paged Attention V1 #
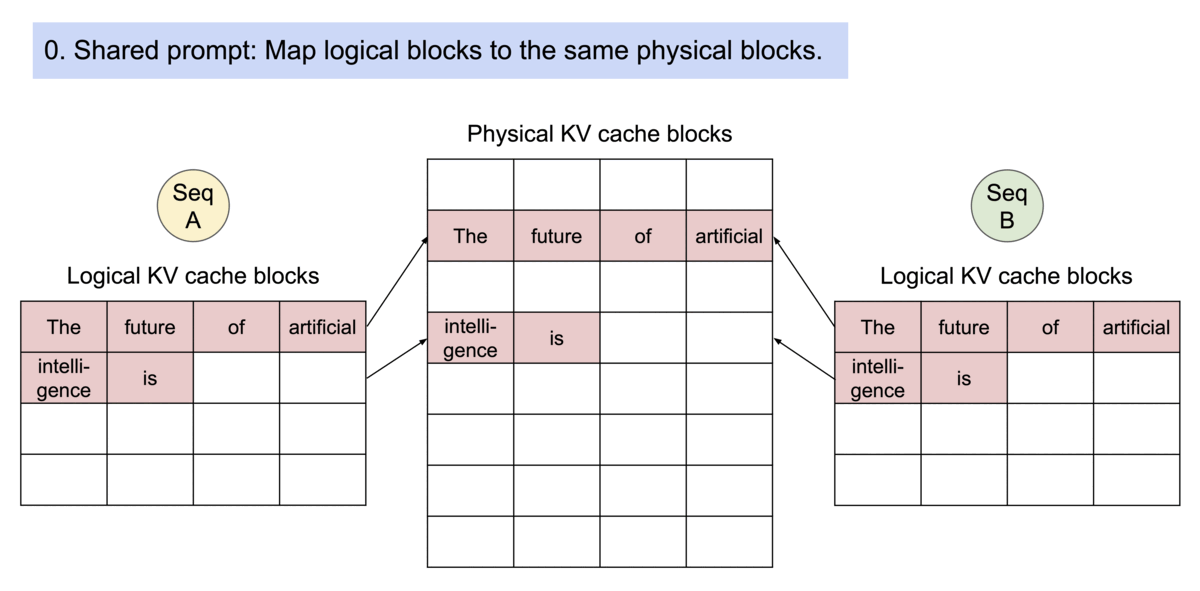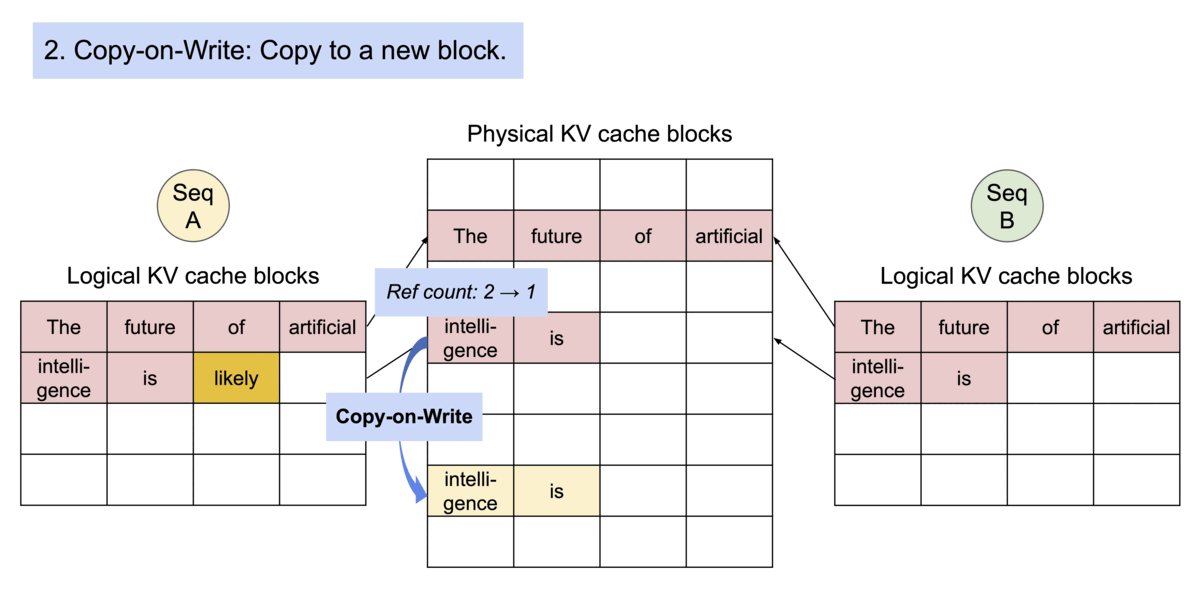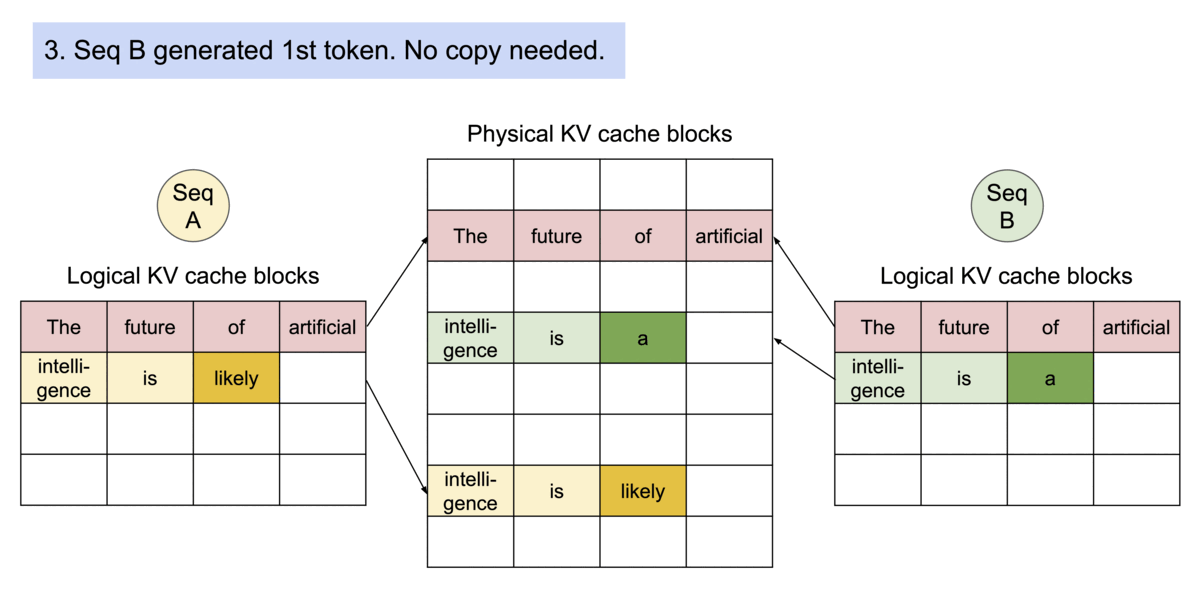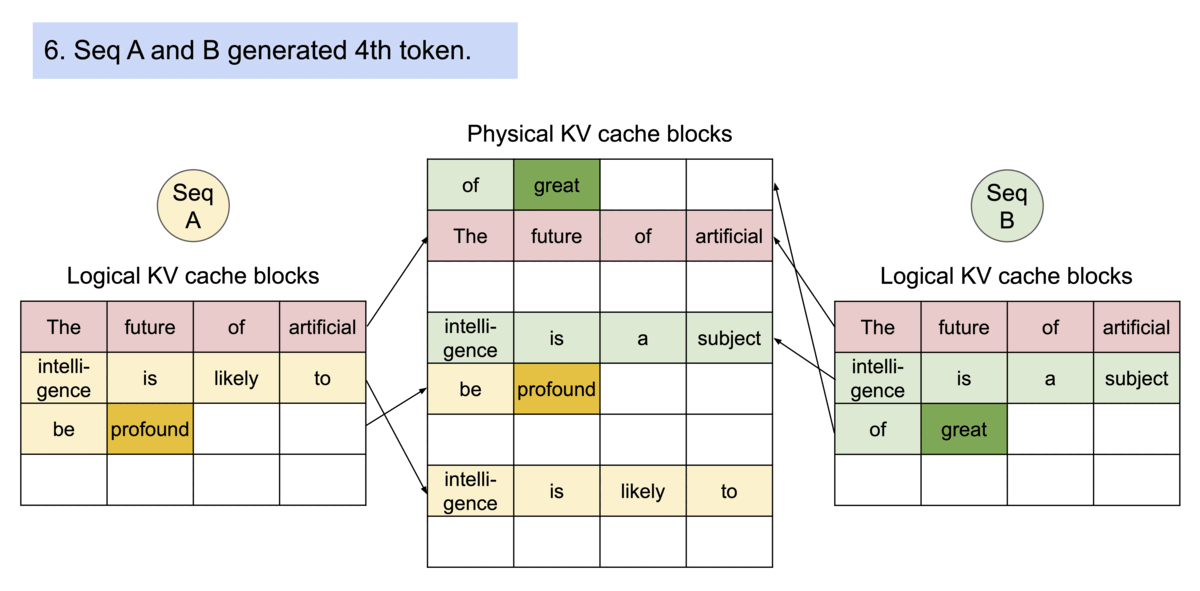
Block table in PA
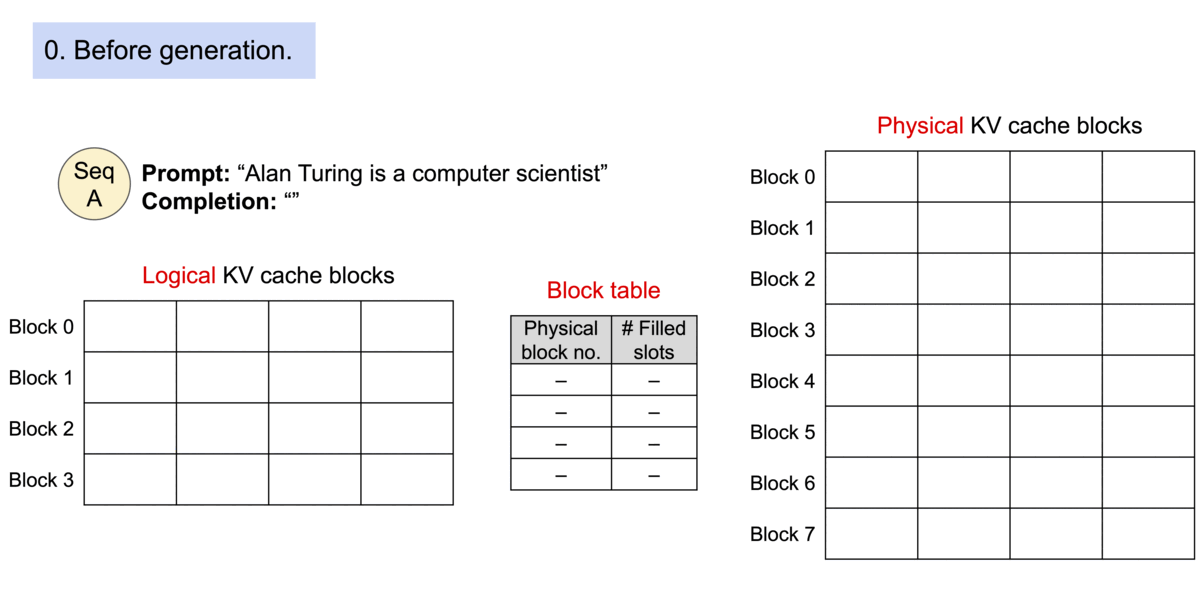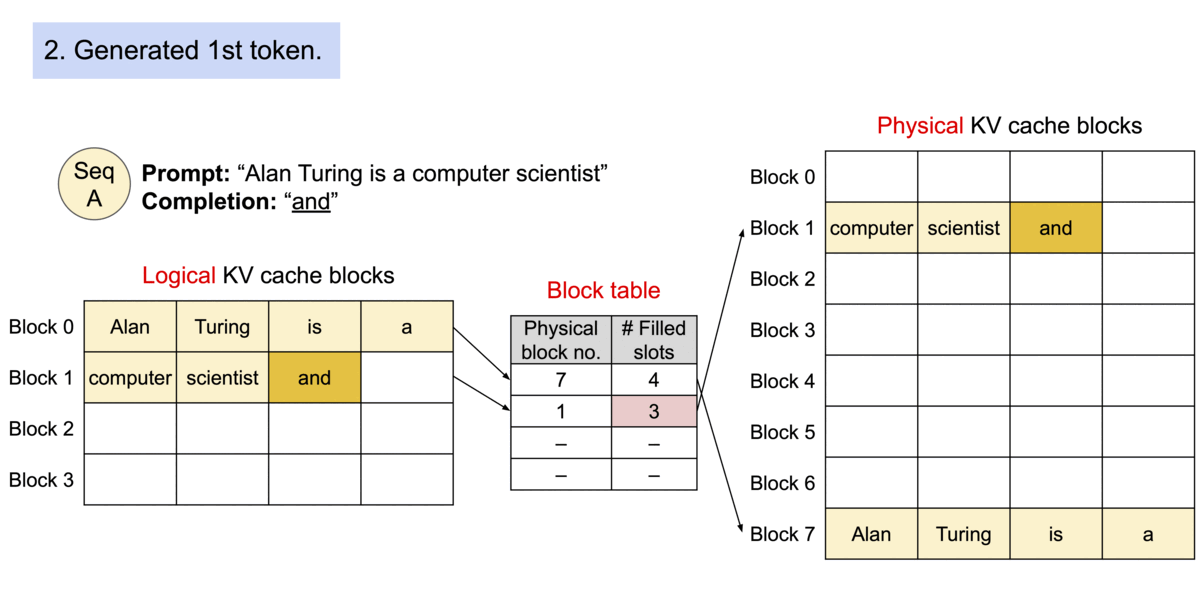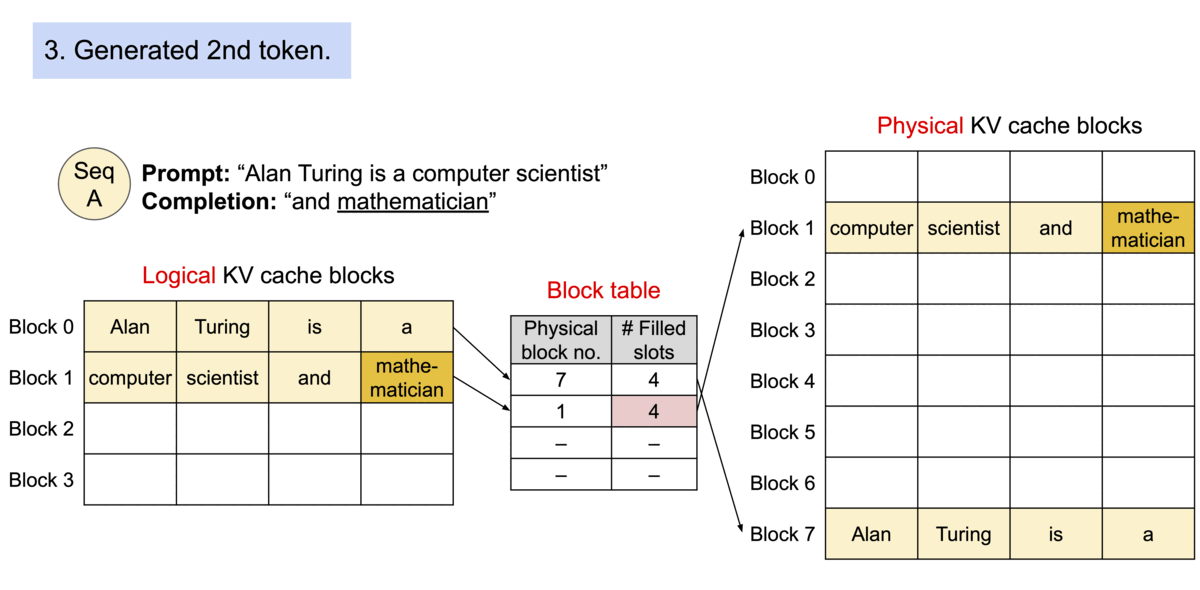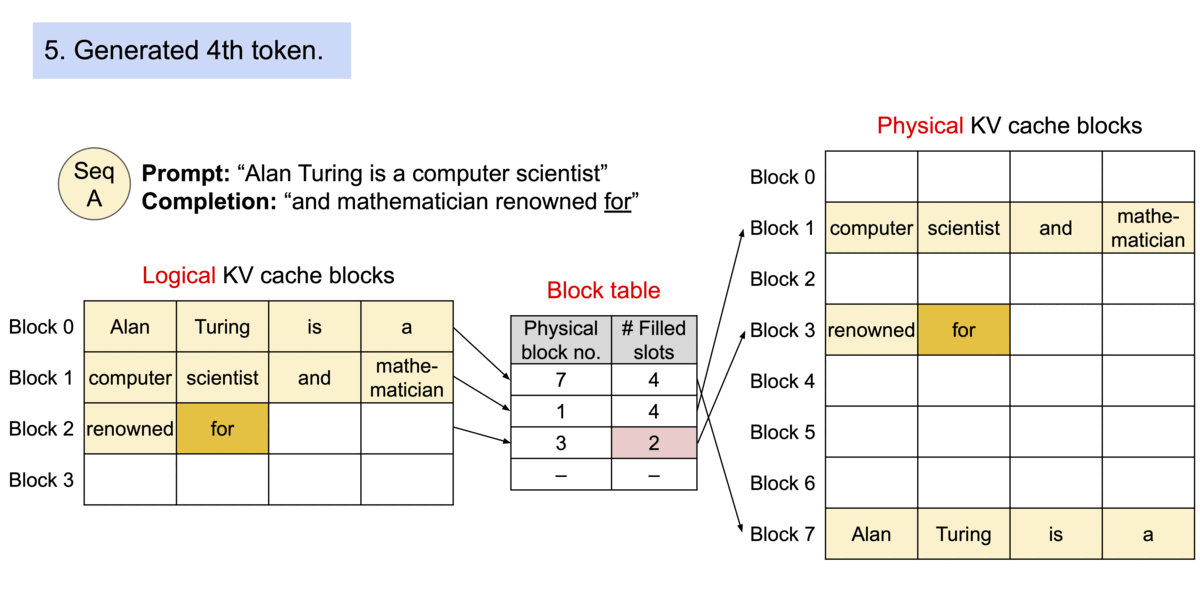
一个 req 中包含多个 seq 时,可以共享blocks
Paged Attention V1 CUDA Kernel(vLLM) #
csrc/attention/attention_kernels.cu
single_query attention 函数
Dispatch逻辑:
- CALL_KERNEL_LAUNCHER_BLOCK_SIZE 根据存储的kv blocksize进行派发,分别是 8, 16, 32
- LAUNCH_ATTENTION_KERNEL 根据注意力头大小HEADSIZE静态派发
并行任务的划分:
- dim3 grid(num_heads, num_seqs, 1)
- dim3 block(NUM_THREADS), 线程数是128,每个 block 负责完成 output 矩阵一行(head_size个元素)结果的 attention 计算
- block 的线程划分为若干个 Warp, 每个 Warp 的32个线程划分为 blk_size 个 thread group
Kernel 输入参数
out[num_seqs, num_heads, head_size]
q[num_seqs, num_heads, head_size]
k_cache[num_blocks, num_kv_heads, head_size/x, block_size, x] # x表示一个向量化的大小,如float16 -> 16 / sizeof(float16) = 8
v_cache[num_blocks, num_kv_heads, head_size, block_size]
head_mapping[num_heads] # 使用MQA, GQA时的kv_head
block_tables[num_seqs, max_num_blocks_per_seq] # 维护各个Q对应KVCache的哪些block
context_lens[num_seqs] # 用于变长
num_head: Q 的 head 数 num_kv_heads:K, V 的 head 数,MHA 的 num_kv_heads = num_head,GQA、MQA 的 num_kv_heads < num_head blk_size # block_size,每个page block存储的元素数量,每个page存(blk_size, num_head,head_size)个K、V的元素
Kernel 的常量定义:
- THREAD_GROUP_SIZE = MAX(WARP_SIZE / BLOCK_SIZE, 1) 通过WARPSIZE / BLOCKSIZE 得到一个thread_group大小。注意这里的BLOCKSIZE不是cuda blocksize,而是一个kv block的大小(默认值16)
- NUM_TOKENS_PER_THREAD_GROUP = (BLOCK_SIZE + WARP_SIZE - 1) / - WARP_SIZE 表示每个thread_group处理多少个token
- NUM_WARPS 表示一个threadblock有多少个warp
- VEC_SIZE 表示向量化大小,保证每个thread_group一次性获取16bytes,MAX(16 / (THREAD_GROUP_SIZE * sizeof(scalar_t)), 1)
- NUM_ELEMS_PER_THREAD = HEAD_SIZE / THREAD_GROUP_SIZE 表示每个thread要负责多少个数据计算
- NUM_VECS_PER_THREAD = NUM_ELEMS_PER_THREAD / VEC_SIZE 表示每个thread负责的数据经过向量化后,一共有多少个vec
- V_VEC_SIZE = MIN(16 / sizeof(scalar_t), BLOCK_SIZE) 每个thread一次性读取16bytes
- NUM_V_VECS_PER_ROW = BLOCK_SIZE / V_VEC_SIZE。对于v_cache[head_size, block_size],表示一行需要几个V_VEC
- NUM_ROWS_PER_ITER = WARP_SIZE / NUM_V_VECS_PER_ROW 表示一个warp可以处理多少行
- NUM_ROWS_PER_THREAD 表示每个thread需要负责多少行
Kernel 代码逻辑:
(1)循环从显存读取\(Q\)到 shared memory:
迭代读取,每 CUDA block 负责读取\(Q\)的一行(head_size 个元素)存入 shared memory。其中,block 的每个 Warp 负责读取 16blk_size 字节的 Q,即每个 thread group 会读取16字节的 Q,16blk_size 字节的 Q 对应 sequence 的一个 head。
const int thread_group_idx = thread_idx / THREAD_GROUP_SIZE;
const int thread_group_offset = thread_idx % THREAD_GROUP_SIZE;
// Load the query to registers.
// Each thread in a thread group has a different part of the query.
// For example, if the the thread group size is 4, then the first thread in
// the group has 0, 4, 8, ... th vectors of the query, and the second thread
// has 1, 5, 9, ... th vectors of the query, and so on. NOTE(woosuk): Because
// q is split from a qkv tensor, it may not be contiguous.
const scalar_t* q_ptr = q + seq_idx * q_stride + head_idx * HEAD_SIZE;
__shared__ Q_vec q_vecs[THREAD_GROUP_SIZE][NUM_VECS_PER_THREAD];
#pragma unroll
for (int i = thread_group_idx; i < NUM_VECS_PER_THREAD;
i += NUM_THREAD_GROUPS) {
const int vec_idx = thread_group_offset + i * THREAD_GROUP_SIZE;
q_vecs[thread_group_offset][i] =
*reinterpret_cast<const Q_vec*>(q_ptr + vec_idx * VEC_SIZE);
}
__syncthreads();
(2)循环从显存读取\(K\)到 register,并计算QK:
- 每个 seq 包含 cxt_length * num_kv_heads * head_size 个元素
- 每个 CUDA block 负责计算一个 seq 的一个 head 的 \(QK^T\), 只需要读取 ctx_length * head_size 个 K 的元素
- 因为页式内存管理,K 在 ctx_length 维度的存储不连续,以 blk_size 个 token 为粒度分布在不同的内存地址,所以需要根据 Q 的 head_idx 和 seq_idx 访问 block_table 找到 K 的 physical_block_num
- K Cache的布局为 [num_blocks, num_kv_heads, head_size/x, block_size, x], 目的是优化写入 shared memory。Q和K的同一行元素被读入寄存器并进行点乘运算后,结果要写入shared memory。如果一个 Warp 中所有线程都计算 Q、K 同一行数据,会导致写入 shared memory 的同一个位置,这将造成 warp 内不同线程顺序地写入。所以 warp 的线程最好计算 Q和K 的不同行数据。在设计 K 布局时,将 block_size 放在比 head_size 更低的维度。由于warp size大于block_size,我们需要将head_size拆分为head_size/x和x两个维度,借x到最低维度,以确保每个线程读入的数据量和计算量都足够大。最后,每个线程组派一个线程去写入shared memory,这样一个warp有blk_size个线程并行写入shared memory,从而增加了shared memory的访问带宽。这种设计策略是为了实现高效的并行计算和内存访问,以提高整体的计算性能。
- 读取 K 需要一个循环,循环中每个CUDA block中的所有 warp 依次访问num_blocks 个 page block。每次迭代:
- 每个 warp 负责访问连续的 blk_size 个 KCache 的行数据(blk_size * head_size个元素)。每个 thread group 负责访问 KCache 的一行,将head_size 个元素读入寄存器
- 寄存器中的Q和K元素进行点乘,结果写入shared memory。一个 CUDA block 的 shared memory 存储了一行 QK^T 的结果,共 ctx_length 个元素
- CUDA block 对 shared memory 中元素进行 max,sum 方式 reduction,然后计算得到 softmax 的结果
代码步骤:
-
group是由block大小决定的,当block>32时,每个warp实现了一个group,否则在一个warp中实现多个group
-
每个warp负责计算一个block KCache,而每个block key shape为 [block_size, num_head, head_size]
-
每个thread_group取一个key,即num_head个元素,计算QK dot
-
只有thread_group的第一个thread负责将QK结果写入shared memory
-
head_idx标记GPU BLOCKs,也即每个GPU Blocks计算一个head
-
num_heads标记使用的GPU BLOCKs总数,也即head num
-
seq_idx标记的是第二维GPU BLOCKs, 也即seq的位置
分配red_smem[2*NUM_WARPS]为reduce所用,保留的是warp内的局部最大值。后面计算了qvec的dot结果保存为qk,先在group内reduce计算得到局部最大值,然后在每个warp内reduce计算得到全局最大值为qk_max。
// 每个warp负责 blocksize * headsize个元素
// block_idx是block cache中的序号(逻辑序号)
for (int block_idx = warp_idx; block_idx < num_blocks; block_idx += NUM_WARPS) {
// TODO(Zhengzekang)
// 定位物理块
const int physical_block_number = block_table[block_idx];
// ...
K_vec k_vecs[NUM_VECS_PER_THREAD];
// 遍历每个thread_group处理多少个token
for (int i = 0; i < NUM_TOKENS_PER_THREAD_GROUP; i++) {
const int physical_block_offset =
(thread_group_idx + i * WARP_SIZE) % BLOCK_SIZE;
const int token_idx = block_idx * BLOCK_SIZE + physical_block_offset;
K_vec k_vecs[NUM_VECS_PER_THREAD];
// 遍历每个thread需要处理多少个VEC
for (int j = 0; j < NUM_VECS_PER_THREAD; j++) {
// vectorized取到key
k_vecs[j] = xxxx;
}
// 计算QKdot,里面包含了一个thread_groupsize的WarpReduceSum,
float qk = scale * Qk_dot<scalar_t, THREAD_GROUP_SIZE>::dot(q_vecs, k_vecs);
// 只有thread_group的第一个thread负责将QK结果写入shared memory
// 并且维护一个qk_max,用于后续softmax
if (thread_group_offset == 0) {
// Store the partial reductions to shared memory.
// NOTE(woosuk): It is required to zero out the masked logits.
const bool mask = token_idx >= context_len;
logits[token_idx] = mask ? 0.f : qk;
// Update the max value.
qk_max = mask ? qk_max : fmaxf(qk_max, qk);
}
}
}
此时各个thread_group已经完成了自己的qk_dot操作,并且都维护了qk_max。下面就需要和其他thread_group做warp shuffle操作,得到一个warp内的qk max值。
由于每个thread_group里的thread内维护的qk_max是一样的,所以warp shuffle只需到 thread_group_size即可停止。并由lane_id = 0的线程将warp里的qk_max存储到smem,最后再做一次warpreduce,得到一个block里的qkmax值,通过shfl_sync广播操作,让每个线程都拿到max
#pragma unroll
for (int mask = WARP_SIZE / 2; mask >= THREAD_GROUP_SIZE; mask /= 2) {
qk_max = fmaxf(qk_max, __shfl_xor_sync(uint32_t(-1), qk_max, mask));
}
if (lane == 0) {
red_smem[warp_idx] = qk_max;
}
__syncthreads();
// TODO(woosuk): Refactor this part.
// Get the max qk value for the sequence.
qk_max = lane < NUM_WARPS ? red_smem[lane] : -FLT_MAX;
#pragma unroll
for (int mask = NUM_WARPS / 2; mask >= 1; mask /= 2) {
qk_max = fmaxf(qk_max, __shfl_xor_sync(uint32_t(-1), qk_max, mask));
}
// Broadcast the max qk value to all threads.
qk_max = __shfl_sync(uint32_t(-1), qk_max, 0);
接下来就是常规的softmax
执行exp(x-qk_max)并得到每个warp上的exp_sum,规约得全局(所有warp)的exp_sum,计算每个节点上的softmax
// Get the sum of the exp values.
float exp_sum = 0.f;
for (int i = thread_idx; i < context_len; i += NUM_THREADS) {
float val = __expf(logits[i] - qk_max);
logits[i] = val;
exp_sum += val;
}
exp_sum = block_sum<NUM_WARPS>(&red_smem[NUM_WARPS], exp_sum);
// Compute softmax.
const float inv_sum = __fdividef(1.f, exp_sum + 1e-6f);
for (int i = thread_idx; i < context_len; i += NUM_THREADS) {
logits[i] *= inv_sum;
}
__syncthreads();
(3)从显存读取\(V\)到 register, 计算 softmax(QK^T)V
和KCache一样,CUDA block 依次访问 num_blk 个 VCahce block 到寄存器,每个 warp 负责 1 个 VCache block,。不过这里不需要以 thread group 为单位访问16字节,而是每个 thread 读取16字节的元素到寄存器,然后与shared memory的 softmax(QK^T)中间结果 对应位置16字节的数据进行点乘,得到一个 float 结果,写到 output 的对应位置中。
为了读写连续,将V_cache转置,shape为:[num_blocks, num_kv_heads, head_size, block_size]
注意这里使用了fp32模式以防止累加过程中的精度损失
// 每个线程一次性读16bytes数据
constexpr int V_VEC_SIZE = MIN(16 / sizeof(scalar_t), BLOCK_SIZE);
using V_vec = typename Vec<scalar_t, V_VEC_SIZE>::Type;
using L_vec = typename Vec<scalar_t, V_VEC_SIZE>::Type;
using Float_L_vec = typename FloatVec<L_vec>::Type;
// 每一行有多少个V_VEC,假设BLOCK_SIZE=8,那么NUM_V_VECS_PER_ROW=1
constexpr int NUM_V_VECS_PER_ROW = BLOCK_SIZE / V_VEC_SIZE;
// 一个WARP一次处理多少行,按照上面假设,这里是32
constexpr int NUM_ROWS_PER_ITER = WARP_SIZE / NUM_V_VECS_PER_ROW;
// 每个thread需要负责多少行,假设headsize=128,那么每个thread要处理4行
constexpr int NUM_ROWS_PER_THREAD = (HEAD_SIZE + NUM_ROWS_PER_ITER - 1) / NUM_ROWS_PER_ITER;
// 提前分配accumulate buffer,用float累加
float accs[NUM_ROWS_PER_THREAD];
#pragma unroll
for (int i = 0; i < NUM_ROWS_PER_THREAD; i++) {
accs[i] = 0.f;
}
for (int block_idx = warp_idx; block_idx < num_blocks; block_idx += NUM_WARPS) {
// ...
#pragma unroll
for (int i = 0; i < NUM_ROWS_PER_THREAD; i++) {
const int row_idx = lane / NUM_V_VECS_PER_ROW + i * NUM_ROWS_PER_ITER;
if (row_idx < HEAD_SIZE) {
const int offset = row_idx * BLOCK_SIZE + physical_block_offset;
V_vec v_vec = *reinterpret_cast<const V_vec*>(v_ptr + offset);
accs[i] += dot(logits_vec, v_vec);
}
}
}
(4)更新最终的结果
将一个block分成上半部分warp和下半部分warp。上半部分warp(warp_id > mid)将自己累加的结果写到shared memory。下半部分warp将之前上半部分warp存到shared_memory 的结果取出,进行累加。这样重复,当warp_idx==0时,将所有结果写回到每一行中。
// Perform reduction across warps.
float* out_smem = reinterpret_cast<float*>(shared_mem);
#pragma unroll
for (int i = NUM_WARPS; i > 1; i /= 2) {
int mid = i / 2;
// Upper warps write to shared memory.
if (warp_idx >= mid && warp_idx < i) {
float* dst = &out_smem[(warp_idx - mid) * HEAD_SIZE];
#pragma unroll
for (int i = 0; i < NUM_ROWS_PER_THREAD; i++) {
const int row_idx = lane / NUM_V_VECS_PER_ROW + i * NUM_ROWS_PER_ITER;
if (row_idx < HEAD_SIZE && lane % NUM_V_VECS_PER_ROW == 0) {
dst[row_idx] = accs[i];
}
}
}
}
__syncthreads();
// Lower warps update the output.
if (warp_idx < mid) {
const float* src = &out_smem[warp_idx * HEAD_SIZE];
#pragma unroll
for (int i = 0; i < NUM_ROWS_PER_THREAD; i++) {
const int row_idx = lane / NUM_V_VECS_PER_ROW + i * NUM_ROWS_PER_ITER;
if (row_idx < HEAD_SIZE && lane % NUM_V_VECS_PER_ROW == 0) {
accs[i] += src[row_idx];
}
}
}
__syncthreads();
// Write the final output.
if (warp_idx == 0) {
scalar_t* out_ptr = out + seq_idx * num_heads *
max_num_partitions * HEAD_SIZE + head_idx *
max_num_partitions * HEAD_SIZE + partition_idx *
HEAD_SIZE;
#pragma unroll
for (int i = 0; i < NUM_ROWS_PER_THREAD; i++) {
const int row_idx = lane / NUM_V_VECS_PER_ROW + i * NUM_ROWS_PER_ITER;
if (row_idx < HEAD_SIZE && lane % NUM_V_VECS_PER_ROW == 0) {
from_float(*(out_ptr + row_idx), accs[i]);
}
}
}
为什么 VCache 的 layout 是 [num_blocks, num_kv_heads, head_size, block_size],和 KCache layout 不一样? 因为 V 要去做点乘的对象在shared memory,只需要读,不涉及并行写。
PA V1 和 Flash Attention 的区别 #
并行任务的划分方式不同
- FlashAttention 用了两层循环,每次写一个 Tile 的 output tensor,而 PA 只有一层循环,每次写一行 output tensor。因为每次迭代都有整行的 QK^T 中间结果,不需要online softmax
- PA V1 设计的 KCache layout 充分利用了 shared memory 写带宽
PA V1 的缺陷 #
不足:
- 不适合 seq 很长的情况,因为没有沿着 ctx_length 或者 batch 维度做切分
- 和MHA相比,MQA和GAQ没有减少对KV Cache的读写次数。读K、V Cache时候只是做了一个head_idx的转换,会重复从显存读相同的head
未完待续…
Reference: