PTQ #
PTQ(Post-Training Quantization),即后训练量化,主要目标是无需对 LLM 架构进行修改或重新训练的前提下,通过量化减少 LLM 的存储和计算复杂度。
主要优势是简单高效,但会在量化过程中引入一定程度的精度损失。
PTQ 分为 权重量化 和 全量化。
权重量化 #
- LUT-GEMM, 仅对权重进行量化以及使用BCQ格式在LLM中优化矩阵乘法,通过提高计算效率来增强延迟降低和性能
- LLM.int8, 采用混合精度分解的量化方法。先做了一个矩阵分解,对绝大部分权重和激活用8bit量化(vector-wise)。对离群特征的几个维度保留16bit,对其做高精度的矩阵乘法
- ZeroQuant, 对权重做group-wise,对激活值做token-wise。用逐层知识蒸馏缓解精度损失(原网络做老师),量化后的网络做学生。和W8A8的普通方法做比较,在BERT和GPT3-style模型上精度更好,还能把权重量化到4bit,但加速效果糟糕
- GPTQ, 对某个 block 内的所有参数逐个量化,每个参数量化后,需要适当调整这个 block 内其他未量化的参数,以弥补量化造成的精度损失。 GPTQ 需要准备校准数据集
- AWQ, 发现对于LLM的性能,权重并不是同等重要的,通过保留1%的显著权重可以大大减少量化误差。在此基础上,AWQ采用了激活感知方法,考虑与较大激活幅度对应的权重通道的重要性,这在处理重要特征时起着关键作用。该方法采用逐通道缩放技术来确定最佳缩放因子,从而在量化所有权重的同时最小化量化误差
权重和激活全量化 #
LLM中激活往往由于异常值的存在而变得更加复杂
- SmoothQuant,观察到不同的token在它们的通道上展示出类似的变化,引入了逐通道缩放变换,有效地平滑了幅度,解决了量化激活的挑战。
LLM.int8() #
LLM.int8()发现当 LLMs 的模型参数量超过 6.7B 的时候,激活中会成片的出现大幅的离群点(outliers),朴素且高效的量化方法(W8A8、ZeroQuant等)会导致量化误差增大,精度下降。但是离群特征(Emergent Features)的分布是有规律的,通常分布在 Transformer 层的少数几个维度。针对这个问题,LLM.int8() 采用了混合精度分解计算的方式(离群点和其对应的权重使用 FP16 计算,其他量化成 INT8 后计算)。虽然能确保精度损失较小,但由于需要运行时进行异常值检测、scattering 和 gathering,导致它比 FP16 推理慢。
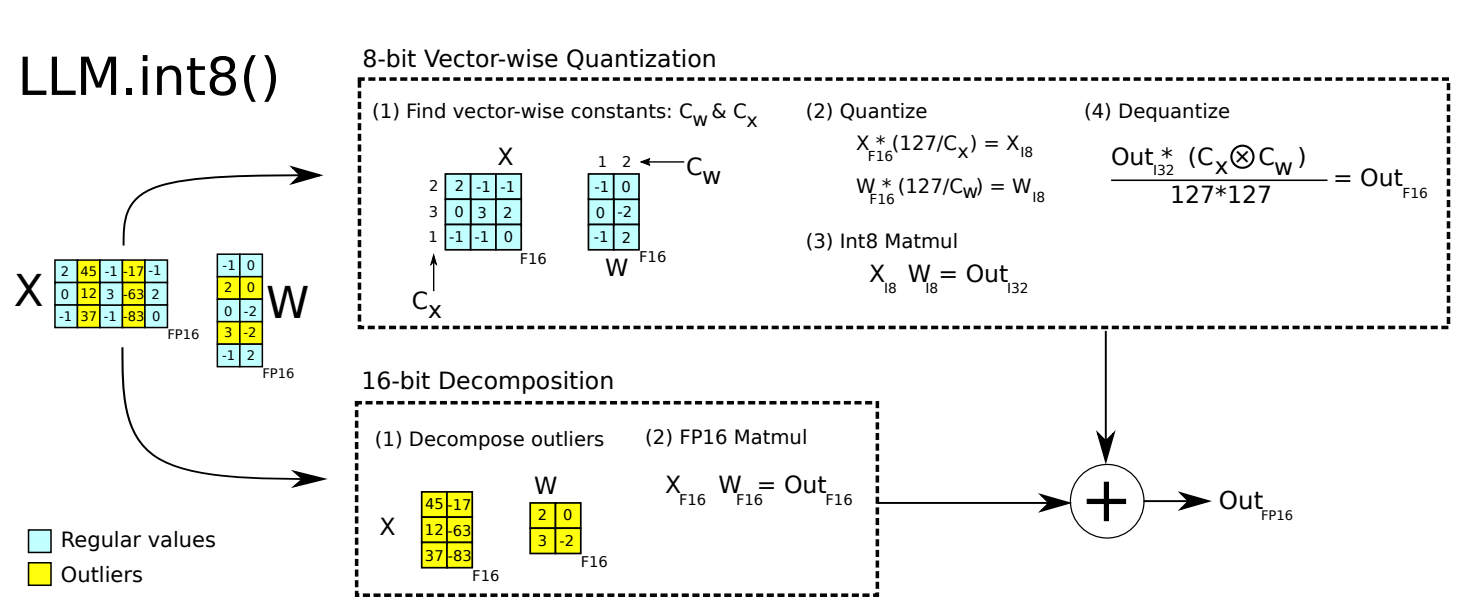
步骤:
- 从输入的隐含状态中,按列提取异常值 (离群特征,即大于某个阈值的值)。
- 对离群特征进行 FP16 矩阵运算,对非离群特征进行量化,做 INT8 矩阵运算;
- 反量化非离群值的矩阵乘结果,并与离群值矩阵乘结果相加,获得最终的 FP16 结果
虽然 LLM.in8() 带来的性能下降微乎其微,但是这种分离计算的方式拖慢了推理速度。对于 BLOOM-176B,相比于 FP16,LLM.int8() 慢了大约 15% 到 23%;对于更小的模型(3B 和 11B),速度差距更为明显,LLM.int8() 慢三倍以上
LLM.int8() 的实现主要在 bitsandbytes 库,transformers 库已经集成了 bitsandbytes 这个量化库,其优点是不需要量化校准数据集,任何模型只要含有 torch.nn.Linear 模块,就可以对其进行开箱即用的量化。
8-bit:
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(
'decapoda-research/llama-7b-hf',
device_map='auto',
load_in_8bit=True,
max_memory={
i: f'{int(torch.cuda.mem_get_info(i)[0]/1024**3)-2}GB'
for i in range(torch.cuda.device_count())
}
)
4-bit:
from transformers import BitsAndBytesConfig
nf4_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
bnb_4bit_compute_dtype=torch.bfloat16
)
model_nf4 = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=nf4_config)
GPTQ #
GPTQ (Generalized Post-Training Quantization),是一种训练后量化 (PTQ) 方法,采用 INT4/FP16 (W4A16) 的混合量化方案,其中模型权重被量化为 int4,激活值保留在 FP16,是一种仅权重量化方法。通过最小化权重的均方误差(基于近似二阶信息)将所有权重压缩到 INT4。推理时,动态地将权重反量化为 FP16。
GPTQ 将权重分组(如:128列为一组)为多个子矩阵(block)。具体的迭代方案是:对某个 block 内的所有参数逐个量化,每个参数量化后,适当调整这个 block 内其他未量化的参数,以弥补量化造成的精度损失,该算法由90年代的剪枝算法发展而来:
OBD (1990):引入 H 矩阵进行神经网络剪枝 OBS (1993):新增权重删除补偿 OBQ (2022):将 OBS 应用到模型量化,并增加分行计算 GPTQ (2023):进一步提升量化速度
GPTQ 量化需要准备校准数据集。
GPTQ 把量化问题视作优化问题,逐层寻找最优的量化权重,使用 Cholesky 分解 Hessian 矩阵的逆,在给定的step中对连续列的块进行量化,并在step结束时更新剩余的权重。
优势:
- int4 量化能够节省接近4倍的内存
- 主要针对 GPU 推理和性能,对 GPU 进行了优化
- 不需要对模型进行重训练
缺陷:
- 对 GPU 要求较高
- 量化预训练模型带来量化误差
- AutoGPTQ 中存在加减一的操作,使得qzeros存在数据溢出的风险:
- 导致 GPTQ 的非对称量化效果甚至不如对称量化,以至于社区大量上传了对称量化的GPTQ权重( TheBloke),这一定程度上拉低了GPTQ算法的表现
- 使得其他非对称量化方法的模型权重(如AWQ),无法安全地转换为 GPTQ 的权重,这使得其他量化方法无法与GPTQ算子兼容(例如exllamav2),社区不得不同时维护多套量化方案。
量化和反量化的步骤:
- 缩放:将输入张量x除以缩放因子scale。这一步是为了将x的值范围调整到预期的量化范围
- 四舍五入:将缩放后的结果四舍五入到最近的整数。这一步将x的值离散化,即将其转换为整数
- 限制范围:使用torch.clamp函数将四舍五入后的结果限制在0和maxq之间,确保量化后的值不会超出预期的量化范围
- 反量化:将量化后的张量减去零点zero,然后乘以缩放因子scale。这一步是为了将量化后的值恢复到原始的值范围
一般来说,GPTQ推荐使用 8-bit 量化及 groupsize = 128。
使用 AutoGPTQ 量化模型 #
AutoGPTQ 是基于 GPTQ 算法、有用户友好型接口的 LLM 量化 toolkit,AutoGPTQ 代码库已被集成到 Transformers 中,可以使用 GPTQ 算法在 8 bit、4 bit、3 bit、2 bit 精度下量化和运行模型
git clone https://github.com/AutoGPTQ/AutoGPTQ && cd AutoGPTQ
pip install -e .
构建 GPTQ 量化模型需要使用训练数据进行校准。以单卡 GPU 进行量化为例:
from auto_gptq import AutoGPTQForCausalLM, BaseQuantizeConfig
from transformers import AutoTokenizer
import logging
logging.basicConfig(
format="%(asctime)s %(levelname)s [%(name)s] %(message)s", level=logging.INFO, datefmt="%Y-%m-%d %H:%M:%S"
)
model_path = "model_path"
quant_path = "quantized_model_path"
quantize_config = BaseQuantizeConfig(
bits=8, # INT4 or INT8
group_size=128, # 量化 group
damp_percent=0.01,
desc_act=False, # set to False can significantly speed up inference but the perplexity may slightly bad
static_groups=False,
sym=True,
true_sequential=True,
model_name_or_path=None,
model_file_base_name="model"
)
max_len = 8192
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoGPTQForCausalLM.from_pretrained(model_path, quantize_config)
# 使用训练数据进行校准
# 样本的数据类型应该为 List[Dict],其中字典的键有且仅有 input_ids 和 attention_mask
data = [{input_ids:"", attention_mask: ""}]
model.quantize(data, cache_examples_on_gpu=False)
# 保存模型, 不支持模型分片
model.save_quantized(quant_path, use_safetensors=True)
tokenizer.save_pretrained(quant_path)
如果使用多个 GPU,需要配置 使用 max_memory 而不是 device_map:
model = AutoGPTQForCausalLM.from_pretrained(
model_path,
quantize_config,
max_memory={i:"20GB" for i in range(4)} # 每个 GPU 的内存配置
)
在 Transformers 中加载 GPTQ 模型 #
Transformers, optimum, peft 已支持 AutoGPTQ,可以直接在 Transformers 中使用量化后的模型。以 Qwen1.5-7B-Chat-GPTQ-Int8 为例:
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen1.5-7B-Chat-GPTQ-Int8", # the quantized model
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen1.5-7B-Chat-GPTQ-Int8")
prompt = "What is AI?"
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
在 vLLM 中加载 GPTQ 量化模型 #
python -m vllm.entrypoints.openai.api_server --model Qwen/Qwen1.5-7B-Chat-GPTQ-Int8
SmoothQuant #
LLM 量化的挑战之一是激活值比权重更难量化,因为权重数据分布一般比较均匀,而激活的异常值多且大让激活值量化变得更艰难,但是异常值只存在少数通道。单一 token 方差很大(异常值会存在于每一个 token 中),单一 channel 方差会小很多。
SmoothQuant 是一种同时确保准确率且推理高效的训练后量化 (PTQ) 方法,可实现 8bit 权重量化(W8A16)、8bit 全量化(W8A8)。核心思想是缩小激活,放大权重,使得激活更容易量化,通常来说由于各类 Norm 的存在,激活的波动范围会远大于权重,因此 SmoothQuant 从激活的参数中提取一个缩放系数,再乘到权重中,结果不变但压缩了激活的变换范围,从而减少了量化误差。它引入平滑因子 s 来平滑激活的异常值,通过数学等效变换将量化难度从激活转移到权重上。
SmoothQuant 对激活进行平滑,按通道(列)除以 smoothing factor,同时为了保持 liner layer 数学上的等价性,以相反的方式对权重进行对应调整。
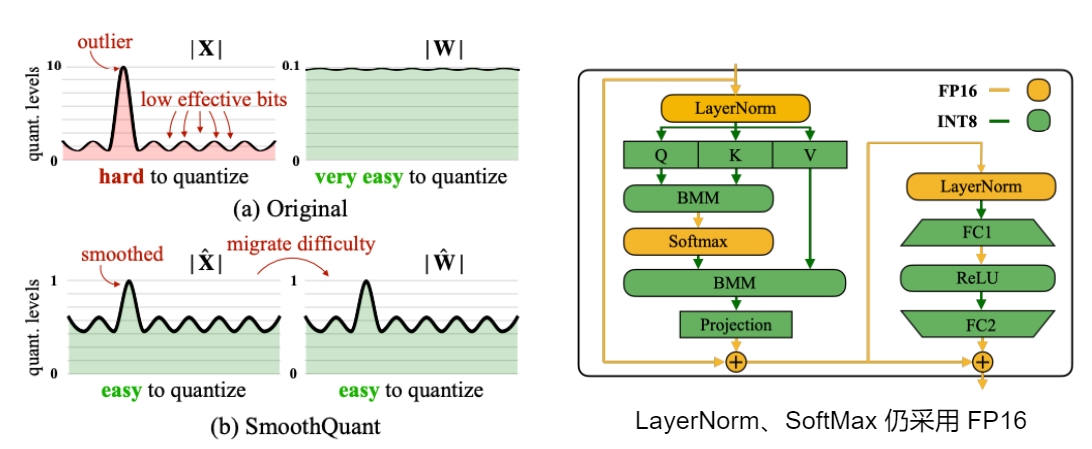
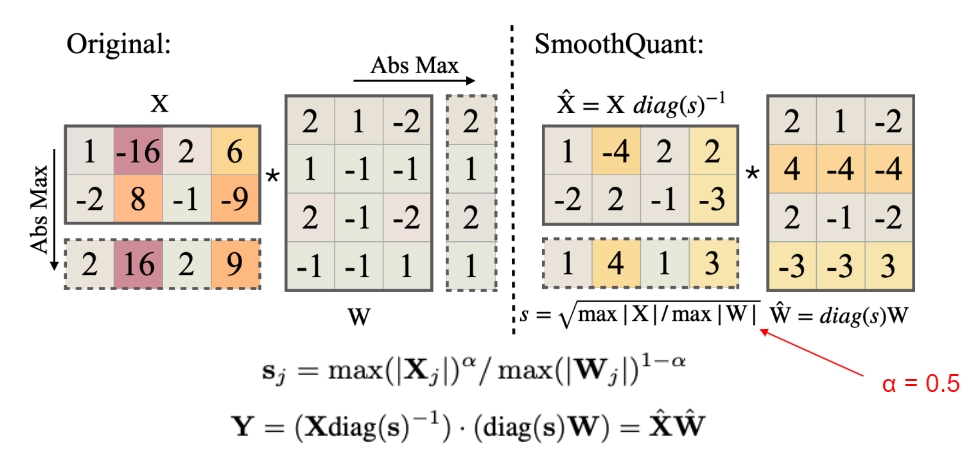
SmoothQuant 证明自己可以无损地量化(8bit)所有超过100B参数的开源LLM。通过集成到PyTorch和FasterTransformer中,与 FP16 相比,获得高达1.56倍的推理加速,并将内存占用减半,并且模型越大,加速效果越明显。
与其他量化方法相比,SmoothQuant 可以保持较高的精度,同时具有更低的延迟。
目前,SmoothQuant 已经被集成到 TensorRT-LLM(NVIDIA) 和 Neural-Compressor(Intel) 中。
AWQ #
AWQ(Activation-aware Weight Quantization), 即激活感知权重量化,是一种硬件友好的、低比特权重量化方法,同时支持 CPU、GPU。
AWQ 源于一个观察,即权重对于LLM的性能并不同等重要:存在约(0.1%-1%)的显著权重(salient weight)对大模型性能影响很大,跳过这1%的显著权重(不量化),可大大减少量化误差。
AWQ 通过观察激活分布而非权重分布来寻找保护显著权重的最佳每通道缩放比例(per-channel),在量化过程中会对特殊权重进行特殊处理以减轻量化过程中的精度损失,在和GPTQ量化保持类似推理速度的同时可以具备更好的精度。
除了官方支持 llm-awq以外,AutoAWQ、vLLM、HuggingFace TGI、LMDeploy、TensorRT-LLM、FastChat 等都支持 AWQ
AutoAWQ #
基于 AWQ 的 量化工具包,与 FP16 相比,AutoAWQ 使用4bit量化将模型速度提高了 3 倍,并将对内存需求降低了 3 倍。Transformers 已经集成了 AutoAWQ
使用autoawq量化模型
from awq import AutoAWQForCausalLM
from transformers import AutoTokenizer
model_path = "facebook/opt-125m"
quant_path = "opt-125m-awq"
quant_config = {
"zero_point": True,
"q_group_size": 128,
"w_bit": 4,
"version":"GEMM"}
# Load model
model = AutoAWQForCausalLM.from_pretrained(model_path)
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
# Quantize
model.quantize(tokenizer, quant_config=quant_config)
加载 awq 模型
from transformers import AutoTokenizer, AutoModelForCausalLM
quant_path="opt-125m-awq"
tokenizer = AutoTokenizer.from_pretrained(quant_path)
model = AutoModelForCausalLM.from_pretrained(quant_path).to(0)
text = "What is AI?"
inputs = tokenizer(text, return_tensors="pt").to(0)
out = model.generate(**inputs, max_new_tokens=5)
print(tokenizer.decode(out[0], skip_special_tokens=True))
GGUF #
GGUF(GPT-Generated Unified Format),以前称为 GGML(General Matrix Multiply Library),GGUF格式较新,可以保留模型版本等其他自定义信息。这两种格式也是PTQ形式的量化算法。允许用户使用 CPU 来运行 LLM,它专注于优化矩阵乘,以提高量化后的计算效率,适用于在资源受限的设备。
加载 GGUF 模型 #
pip install ctransformers[cuda]
from ctransformers import AutoModelForCausalLM
from transformers import AutoTokenizer, pipeline
# Use `gpu_layers` to specify how many layers will be offloaded to the GPU.
model = AutoModelForCausalLM.from_pretrained(
"TheBloke/zephyr-7B-beta-GGUF",
model_file="zephyr-7b-beta.Q4_K_M.gguf",
model_type="mistral", gpu_layers=50, hf=True
)
tokenizer = AutoTokenizer.from_pretrained(
"HuggingFaceH4/zephyr-7b-beta", use_fast=True
)
# Create a pipeline
pipe = pipeline(model=model, tokenizer=tokenizer, task='text-generation')
# Inference
outputs = pipe(prompt, max_new_tokens=256)
print(outputs[0]["generated_text"])
总结 #
| Method | Type | Need Dataset | Scale 粒度 | DateType | Hardware |
|---|---|---|---|---|---|
| LLM.int8() | PTQ | No | per-channel | 8bit,4bit | GPU |
| GPTQ | PTQ | Yes | per-group | 8bit,4bit | GPU |
| SmothQuant | PTQ | No | per-tensor, per-token | 8bit | GPU |
| AWQ | PTQ | No | per-channel | 4bit | GPU,CPU |
Reference