Self-Attention #
对于self-attention,由于 Q, K, V 都来自输入 X ,在计算 \(QT^T\) 时,模型很容易关注到自身的位置上,也就是 \(QT^T\) 对角线上的激活值会明显比较大, 这会削弱模型关注其他高价值位置的能力,也就限制模型的理解和表达能力。MHA 对这个问题有一定的缓解作用。
MHA #
MHA(multi-head attention)
QKV 经过线性变换后,将他们分别在 hidden states 维度上切分成 heads 份。
MHA 相比单头的情况,相当于只是把 QKV 切成多份并行计算了,对于实际需要缓存的大小没有影响
KV Cache #
Decoding阶段,下一个step的输入其实包含了上一个step的内容,而且只在最后面多了一个token的数据,下一个step的计算应该也包含了上一个step的计算。
KV Cache 的目的:空间换时间,用缓存把需要重复利用的中间计算结果存下来,减少重复计算。而 K 和 V 就是要缓存的对象。
Q K V
对于输入长度为 \(seq\) ,层数为 \(L\) ,hidden size为 \(d\) 的模型:
- 当 batch size=1 时
- 需要缓存的参数量为: 2Ls*d ,其中 2 表示 K + V
- 需要的空间为(使用半精度浮点数 float16):22Lsd Bytes ,其中第一个 2 表示 float16 占用 2 Bytes
- 当 batch size=B 时
- 需要缓存的参数量为: 2LsdB
- 需要的空间为(使用半精度浮点数 float16):22Lsd*B Bytes
- MHA 相比单头的情况,相当于只是把 QKV 切成多份并行计算了,对于实际需要缓存的大小没有影响
- GQA、MQA [Todo]
以Llama2 7B为例,L=32, d=4096,此时每个 token 需要的 cache 空间为 524,288 Bytes(512 KB),当 s=1024, batch size=1 时,需要 512 MB
主流显卡配置:
- NV A100(Ampere Arch),HBM2e 40/80GB,L2 Cache 40MB, CUDA Cores - 16896/14592
- NV H100(Hopper Arch), HBM2e/HBM3 80GB, L2 Cache 50MB, CUDA Cores 6912
- NV V100(Volta Arch), HBM2 16/32GB, L2 Cache 6MB, CUDA Cores 5120
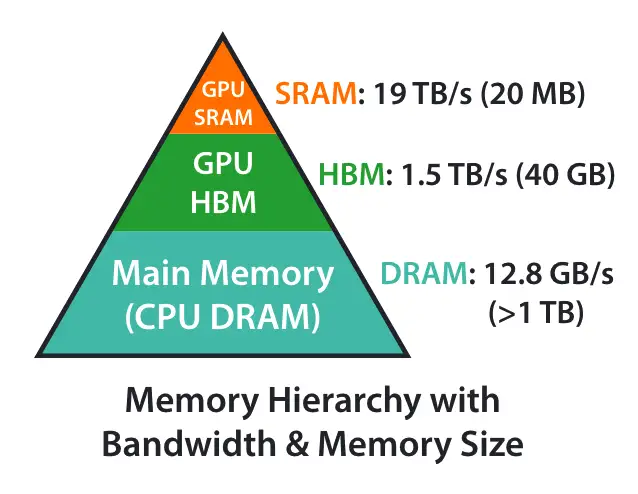
H100也只有50M的L2 Cache,只能支持Llama2 7B共100个tokens的seq,超出L2 Cache的部分只能走到显存中去了,但是 HBM 的 bandwidth 比 L2 Cache 小多了,A100 memory bandwidth 如下图所示:
MQA #
《Fast Transformer Decoding: One Write-Head is All You Need》
Q 经过线性变换后,MQA 只对 Q 进行 多个 head 的切分,每个 head 的 Q 的维度变为 \(Q_s*(d/heads)\), K和V并不切分,而是线性变换时直接把hidden state维度降低为 d/heads, 然后 heads 个 Q 分别于 同一份 K,V 继续宁 attention 计算,最后将结果 concat 起来。
比如在Llama2 7B中用了32个头,MQA后,1024个 tokens 需要 KVCache 就变成MHA 的 1/32,即 512MB/32=16MB,基本可以全部放入A100的L2 Cache
由于共享了多个头的参数,限制了模型的表达能力,MQA虽然能好地支持推理加速,但是在效果上略略比MHA差一点
GQA #
《GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints》
GQA(Grouped-Query Attention)提出了一个折中的办法,既能减少 MQA 的损失,又比 MHA 需要更少的缓存。
GQA里, Q 还是按原来MHA/MQA的做法不变,但是 用多份 K和V,不过数量小于 Q 的 heads。相当于把 Q 的多个头给分了group,同一个group内的 Q 共享同一套 KV,不同group的 Q 所用的 KV 不同。
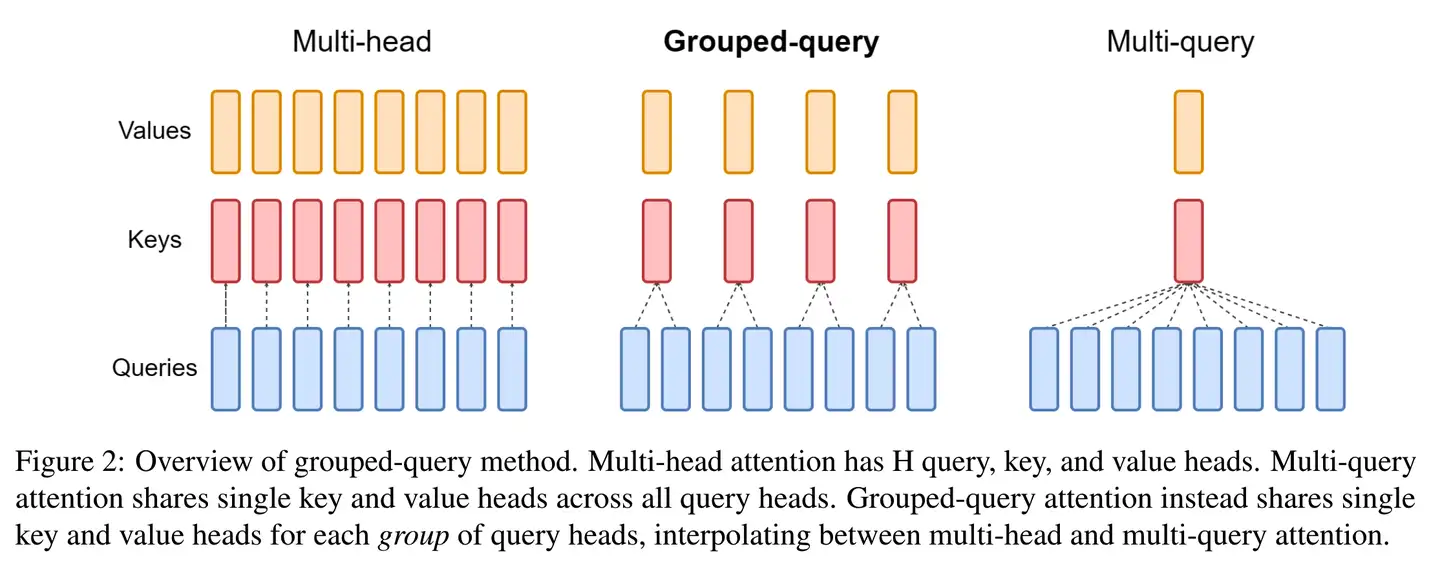
GQA的速度相比MHA有明显提升,而效果上比MQA也好一些,能做到和MHA基本没差距。Llama2 70B 用的就是GQA。
未完待续…
Todo: 代码,GQA量化计算
Reference: